又称80/20法则(The 80-20 rule)
对于许多现象来说,有 80% 的后果都是 20% 的原因造成的。
在软件开发中的体现是: 代码中80%的错误都是由代码中的20%引起的。
另外,公司80%的工作是由20%的员工完成的。问题是你并不总是清楚谁是那20%。
又称80/20法则(The 80-20 rule)
对于许多现象来说,有 80% 的后果都是 20% 的原因造成的。
在软件开发中的体现是: 代码中80%的错误都是由代码中的20%引起的。
另外,公司80%的工作是由20%的员工完成的。问题是你并不总是清楚谁是那20%。
该原则还是比较打击人的,特别是你碰巧正在经历的话。
在等级制度中,每个员工都倾向于提升到他无法胜任的等级
在各种组织中,由于习惯于对在某个等级上称职的人员进行晋升提拔,因而雇员总是趋向于被晋升到其不称职的地位。
一旦组织中的相当部分人员被推到了其不称职的级别,就会造成组织的人浮于事,效率低下,导致平庸者出人头地,发展停滞。
在密码学中,即使一个系统中的所有东西都是公开的(密钥除外),该系统也应当是安全的。
这就是非对称加密的主要原则。
密码学上的柯克霍夫原则(Kerckhoffs’s principle,也称为柯克霍夫假说、公理、或定律)系由奥古斯特·柯克霍夫在19世纪提出:即使密码系统的任何细节已为人悉知,只要密匙(key,又称密钥或密钥)未泄漏,它也应是安全的。 信息论的发明者克劳德·香农则改成说:“敌人了解系统”,这样的说法则称为香农箴言。 它和传统上使用隐密的设计、实现、或其他等等来提供加密的隐晦式安全想法相对。
依据柯克霍夫原则,大多数民用保密都使用公开的算法。 但相对地,用于政府或军事机密的保密器通常也是保密的。
柯克霍夫为军用保密器所设计的这六个原则是:
布鲁斯·施奈尔将这个想法延伸,认为除了密码系统之外,任何保安系统都是这样:试图使用隐密物来保密一些东西,都会制造了失败的根源。若以依赖隐密物或隐密方式的隐密性为主,一旦被公开或复制后即可能有遭到破解的危险
埃里克·雷蒙则将它引伸到开放源代码软件,称一套未假定敌人可获得源代码的信息安全软件并不可靠,因此,“永无可信的封闭源码”。[1]反过来说,开放源码比封闭源码更安全。此种论点称为透明式的安全(security through transparency)
以Linux之父林纳斯·托瓦兹(Linus Torvalds)的名字命名,该定律表述为:
众目睽睽之下,一切 bug 都无所遁形
这个定律出自著名的文集《大教堂与集市》,这个文集对比了两种不同的开源软件开发模型。
被公开审查、测试的代码越多,各种形式的错误就能更快地被发
每一美元所能买到的电脑性能,将每隔24个月翻一番。
最流行的版本是:
集成电路上可容纳的元器件的数目,约每隔18个月便会增加一倍。或计算机的处理性能每隔两年翻一倍。
现在已经失效
90-90法则(ninety-ninety rule,九九定律,99定律)是计算机编程和软件工程领域的一个有名的法则,出自于一句幽默的格言:
“ (开发软件时)前90%的代码要花费90%的开发时间,剩余的10%的代码要再花费90%的开发时间。
The first 90 percent of the code accounts for the first 90 percent of the development time. The remaining 10 percent of the code accounts for the other 90 percent of the development time.”
——Tom Cargill,贝尔实验室
合计180%的时间总量用看似荒诞的形式指出了软件开发项目里一个臭名昭著的倾向-完成时间常常严重超出预期时间表。这一格言体现出了软件工程的对编程项目的简单与困难部分的时间分配太过粗糙的问题,也揭示了许多项目拖延的原因(即对困难部分没有足够的估计)。换句话说,完成一个项目要花比预期的更多的时间和代码。
这一法则被认为是贝尔实验室的Tom Cargill所提出,后来因为Jon Bentley在《ACM通讯》上的“编程珠玑”(Programming Pearls)专栏的“可靠性法则”(Rule of Credibility)一文而流行[1]。这句格言也收录在Jon Bentley后来出版的“编程珠玑II”(More Programming Pearls)一书中[2]。
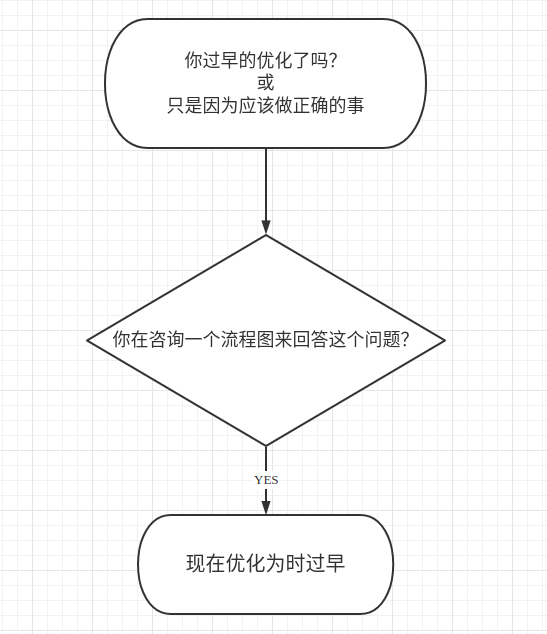
渐进式迭代优化,先把代码写出来,定位瓶颈所在,然后优化它。

我之前的工作更多集中在架构设计及性能调优方面,会更多的鼓励研发人员追求极致。最近在业务线开展工作,在这个问题上有了一些新的体会。
软件开发中最难的是搞清楚到底该做什么。
研发人员都喜欢编写代码和构建应用,成本高且供不应求。 确保研发人员充分利用时间是最大的挑战。 我们最不希望发生的是发布用户不喜欢或不起作用的代码。 那应该花多少时间专注于性能调优和优化呢?
如果不进行任何性能调整或优化,新产品发布可能是一场彻底的灾难。 想一想有段时间全国人民是怎么骂12306的。
我们也不想浪费大量时间在无关紧要的事情上进行性能优化。 快速迭代业务需求显然更加重要。
然而实际工作中,很多最初设计不好的系统很多时候根本没法优化。架构不合理,性能上不去。重构?基本就是完全重写!
一、什么是过早优化
过早优化是试图在为时尚早的阶段提高效率的行为。过早的优化尝试通常会导致适得其反,并导致浪费大量资源,如时间、金钱和精力,同时也增加了未来出问题的可能性。
过早优化的概念在软件工程领域占据突出地位。 “过早优化是万恶之源”是软件开发人员的一句名言。 它来源于Donald Knuth的书《计算机编程艺术》(最早由Tony Hoare提出),以下是引用:
“The real problem is that programmers have spent far too much time
真正的问题是程序员花了太多时间
worrying about efficiency in the wrong places and at the wrong times;
premature optimization is the root of all evil (or at least most of it) in
programming.”
在错误的地方和错误的时间担心效率;
过早的优化是万恶之源(或至少大部分)
编程。
这句关于过早优化的原话来自于20世纪60年代出版的书。那是一个不同的时代,那时大型机和穿孔卡很常见,CPU处理周期很稀缺。所以程序优化得不好,可能会运行很长时间。
过早优化在今天该怎么理解
今天,大多数开发团队都习惯于不断地量产代码并快速迭代,采用敏捷开发方法。如果软件中存在错误,可以很容易地将修复程序部署到Web服务器上。
现代研发过程中仍然存在过早优化的情绪。过早优化是开发人员应该一直考虑的事情,是在日常工作中应该尽量避免的事情。 防止过早优化在大型机时代适用,今天仍然适用。
一个典型的例子是一家创业公司花费大量时间试图找出如何扩展其软件以满足数百万用户。 这是一个非常值得考虑的问题,但不一定要付诸行动。 在担心处理数百万用户之前,你需要确保100个用户喜欢并且想要使用你的产品。 需要首先验证用户反馈。
因此业务模式在反复试错或高速迭代阶段,过多的优化,显得很不划算。身处业务线,经常感到被需求压得喘不过气,其实是因为产品同学会更多的关注用户需求,关注业绩提升。
瓜子作为一个有一定规模的公司,即使新开辟的业务,也会有一定规模的用户基础。Knuth’s的这句话(过早优化是万恶之源),显然不能简单的理解为完全不管性能,先开发业务,再推倒重构。
很多人理解错了
随着计算机系统性能从MHz,数百MHz到GHz的增加,计算机软件的性能已经不是最重要的问题(落后于其他问题)。今天,有些软件工程师将这个格言扩展到“你永远不应该优化你的代码!”,他们发现,有时候代码怎么写似乎问题都不大。
然而,在许多现代应用程序中发现的臃肿和反应迟钝的问题,迫使软件工程师重新考虑如何将Hoare的话应用于他们的项目。
查尔斯库克(http://www.cookcomputing.com/blog/archives/000084.html)的一篇简短的文章,其中一部分我在下面转载,描述了在Hoare的陈述中的问题:
我一直认为这句话经常导致软件设计师犯严重错误,因为它已经被应用到了不同的问题领域。这句话的完整版是“We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil.”
我同意这一点。在性能瓶颈明显之前,通常不值得花费大量时间对代码进行细枝末节的优化。但是,在设计软件时,应该从一开始就考虑性能问题。一个好的软件开发人员会自动做到这一点,他们大概知道性能问题会在哪里出现。没有经验的开发人员不会关注这个点,错误地认为在后期进行一些微调可以解决任何性能问题。
Hoare和Knuth真正说的是,软件工程师在担心微观优化(比如一个特定语句消耗多少CPU周期)之前,应该先担心其他问题(比如好的架构设计和这些架构的良好实现)。
二、过早优化的原因
人们过早地优化事物有很多原因:
1、过早优化出现在一些相对容易解决的问题。
例如,有人对应用程序有所了解,但不确定如何开发它,那么他可能花费大量时间考虑他可以处理的不重要的事情,例如徽标设计会是系统看起来变得高大上。我以前在国企貌似经常发生这样的事。
2、过早优化是一种“美好的愿景”。
例如,想要开始新的爱好的人,如打羽毛球,可能会花费数小时挑选高级装备并在他们开始训练之前规划未来的行动方案,因为这样做很有趣,而且比实际开始训练更简单!在球馆时不时就能看到,除了球技其它都很专业的“爱好者”。
3、过早优化是由于未能正确对任务进行优先级排序。
例如,正在开发软件的人可能过早地优化事情,不是因为要解决(架构、性能)问题,而是因为他们根本不知道如何制定各个研发阶段的计划,识别出各个阶段应该做的工作。
三、怎么做
前几天QCon的围炉夜话,听毕玄说,“09年之前,阿里的技术团队都处于陪(业务)跑状态”。公司在不同阶段,技术团队的重心会不同。初创阶段更多重视业务,业务稳定(垄断)阶段更重视技术本身。
有经验的管理者会通过职位设置,研发力量投入比例来调节业务与“优化”之间的关系。从组织的角度,是希望大多数同学做好本职工作就能很好的平衡业务与“优化”之间的关系。例如在公司发展的某个阶段,出现了架构师这个角色。
作为研发工作的具体参与者和执行者该怎么做呢?从本质上讲,在确定是否应该优化某些内容时,应该考虑以下几个因素,应该问自己的几个重要问题:
1、为什么要优化?
你认为在这个阶段,这种优化是必要的,这意味着它将对你的工作产生显著的、积极的影响,还是你现在仅仅关注它,因为你试图避免处理其他事情?
2、优化的好处是什么?
从优化中你能得到什么?
3、优化的成本是多少?
为了进行这种优化,你需要花费什么资源?
4、优化可能带来的负面后果是什么?
这种优化在将来会给你带来什么样的问题?
5、这种优化有多大可能会过时?
你现在正在做的优化工作以后是否有重大意义,或者这种优化是否可能过时?请注意,仅仅因为某些东西稍后可能会过时并不意味着你现在不应该处理它,但是这种情况发生的可能性,它发生之前需要的时间以及你在此期间将获得的好处,都是你决定是否优化应考虑的因素。
6、推迟这种优化有哪些优点和缺点?
推迟这个特定的优化有什么坏处吗?或许以后你会获得更多的相关信息,你会更好地处理它?
7、你还能做什么?
如果你不把时间和资源花在优化上,你会把它们花在什么上?如果你有其他的事情可以做,你是否从中获益更多?
基于这些标准,可以对必须完成的不同任务进行优先级排序,并找出在哪个阶段应该处理哪些任务,以确保避免过早地进行优化。
但是,每次评估潜在任务时,不必问自己所有这些问题。小任务尤其如此,与使用所有这些标准进行评估相比,简单地完成一个2分钟的小任务可能花费更少的时间和精力。
要意识到这些考虑因素,在必要时至少在某种程度上使用它们来评估任务。任务看起来越大,需要的资源越多,或它将产生的影响越大,你应该越谨慎,应该越多地使用这些标准来评估它。
四、并非所有优化都为时过早
避免过早优化并不意味着你应该完全避免优化。相反,它只是意味着在决定投入资源优化某些东西之前,应该仔细考虑。
人们经常重复“过早优化是万恶之源”的观点,而没有注意到完整的引用,其中说“我们应该忘记细枝末节的优化。在97%时间,过早的优化是所有邪恶的根源。然而,我们不应该在那个关键的3%中放弃我们的机会”。
这意味着评估情况并决定优化某些东西是完全合理的,即使它处于相对较早的阶段。例如你认为小的修改可以带来显着的好处,或者优化可以解决你工作中遇到的瓶颈,或者不优化可能会导致显着的技术债务。
在关于该主题的原始引用中,说这个概念适用于大约3%的情况,但是有效优化的临界值可能高于或低于这个值。例如,一个具有共识原则是Pareto原理(二八规则),在这种情况下,表明80%的积极成果将来自你20%的工作(多做点优化工作也没问题)。
总的来说,为了避免过早优化,应该首先评估情况,并确定在那个时间点是否需要预期的优化。但是,这种方法不应成为完全避免优化的借口,而应该作为尽可能有效地确定任务优先级的方法。
五、总结
过早优化是试图为时尚早的阶段提高效率的行为,例如,尽管有更重要的任务需要你去处理,你却在业务的一些琐碎的方面开展工作。
过早优化是有问题的,因为它会导致你浪费资源,气馁,在你没有足够的信息时采取行动,或者陷入次优的行动过程中。
人们过早地优化事物的最常见原因是没有正确地确定任务优先级,或者过早优化对于他们来说相对容易处理,这个优化即使不必要也能接受。
为了避免过早地优化事情,在开始之前,你应该确保问问自己为什么要优化,这样做的成本和好处是什么,这种优化可能带来的负面后果是什么,等待的优点和缺点是什么,以及你还可以做些什么。
记住,这并不意味着你应该完全避免优化,而是应该仔细考虑并评估情况,然后再决定进行某种优化。
参考
知识点导图 图片地址
m9rco/algorithm-php php实现算法
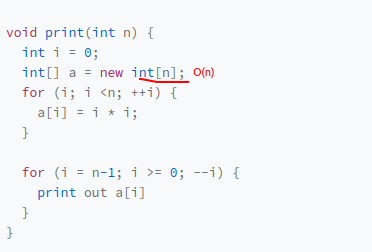
测试环境的硬件和数据规模会影响算法的测试结果,因此需要不用具体的测试数据测试,粗略的估计算法执行效率的方法(复杂度表示法)分为时间复杂度,空间复杂度
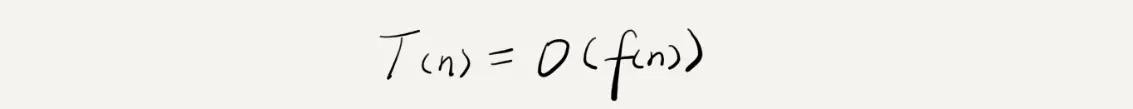
T(n) = O(f(n))
#渐进时间复杂度(时间复杂度)公式说明
T(n)所有代码的执行时间,n表示数据规模大小(循环处理次数),f(n)每行代码执行次数总和,f(n)是运算形式的表达式(例:(2n+2)),O表示代码执行时间T(n)和f(n)表达式成正比
公式表示代码执行时间随数据规模增长的变化趋势具体分析案例
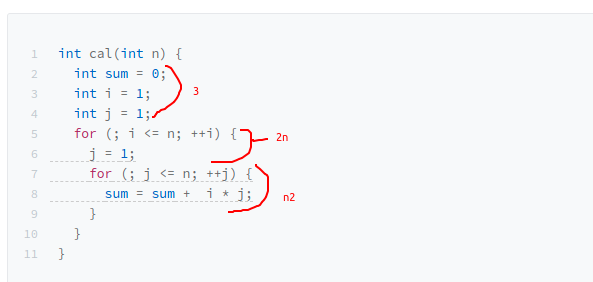
时间复杂度分析方法
1.只关注循环次数最多的一段代码
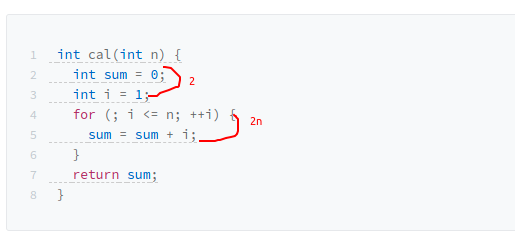
2.加法法则:总复杂度等于量级最大的那段代码的复杂度,因为数据规模参数只有n

3.乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
如果 T1(n)=O(f(n)),T2(n)=O(g(n));那么 T(n)=T1(n)T2(n)=O(f(n))O(g(n))=O(f(n)*g(n))
假设 T1(n) = O(n),T2(n) = O(n2),则 T1(n) * T2(n) = O(n3)
可以把乘法法则看成是嵌套循环
案例

常量阶O(1) ,代码的执行时间不随 n 的增大而增长,这样代码的时间复杂度我们都记作 O(1);一般情况下,只要算法中不存在循环语句、递归语句,即使有成千上万行的代码,其时间复杂度也是Ο(1)
对数阶O(logn) 、线性对数阶O(nlogon)
i=1; while (i <= n) { i = i * 2; }
//通过 2x=n 求解x,x=log2n 时间复杂度就是 O(log2n)。
i=1; while (i <= n) { i = i * 3; }
//通过 3x=n 求解x,x=log3n 时间复杂度就是 O(log3n)。变量 i 的值从 1 开始取,每循环一次就乘以 2。当大于 n 时,循环结束,变量 i 的取值就是一个等比数列
不管是以 2 为底、以 3 为底,还是以 10 为底,我们可以把所有对数阶的时间复杂度都记为 O(logn),对数之间是可以互相转换的,log3n 就等于 log32 * log2n,所以 O(log3n) = O(C * log2n),其中 C=log32 是一个常量。基于我们前面的一个理论:在采用大 O 标记复杂度的时候,可以忽略系数,即 O(Cf(n)) = O(f(n))。所以,O(log2n) 就等于 O(log3n)。因此,在对数阶时间复杂度的表示方法里,我们忽略对数的“底”,统一表示为 O(logn)
一段代码的时间复杂度是 O(logn),我们循环执行 n 遍,时间复杂度就是 O(nlogn) 了,O(nlogn) 也是一种非常常见的算法时间复杂度,如:归并排序、快速排序
线性阶O(n)
平方阶O(n2) 立方阶O(n3)…K次方阶O(nk)
O(m+n)、O(m*n)…

代码的复杂度由两(多个)个数据的规模决定,无法事先评估 m 和 n 谁的量级大,所以我们在表示复杂度的时候,就不能简单地利用加法法则,代码的时间复杂度就是 O(m+n)
时间复杂度为非多项式量级的算法问题叫作 NP(Non-Deterministic Polynomial,非确定多项式)问题
当数据规模 n 越来越大时,非多项式量级算法的执行时间会急剧增加,求解问题的执行时间会无限增长。所以,非多项式时间复杂度的算法其实是非常低效的算法,不常用
指数阶O(2n)
阶乘阶O(n!)
渐进空间复杂度(asymptotic space complexity),表示算法的存储空间与数据规模之间的增长关系
常见的空间复杂度就是 O(1)、O(n)、O(n2 ),像 O(logn)、O(nlogn) 这样的对数阶复杂度平时都用不到
狭义,数据结构是计算机中组织和存储数据的方式,是计算机科学中的理论体系。维基百科
广义,编程语言基于数据结构理论,实现了各自的数据结构,他们之间存在差异。数据结构和算法先于编程语言出现。编程语言中是一些数据类型,并不能跟数据结构和算法书籍中讲到的经典数据结构,完全一一对应。
举例说明:
c/c++中的数组是标准的数据结构
php中的数组是数据类型,底层实现是散列表(Hash Table)
直线型数据结构,数据排成像一条线,线性表上的数据最多只有前和后两个方向。
扩展阅读什么是线性表
用一组连续的内存空间,存储相同数据类型的数据;
支持使用下标随机访问数据,根据下标随机访问的时间复杂度为 O(1)
为了保持内存的数据连续性导致插入,删除两个操作比较低效O(n);标记删除法,每次删除不真正的搬移数据,只是记录数据已删除,当数组没有更多内存空间存储数据时, 才真正触发搬移数据。
标记删除法思想的应用,在数据库删除数据的时候也可以借鉴,如果
C语言中访问不存在下标的数组,会出现访问越界问题,
PS:PHP中的数组
PHP 中的 array 实际上是一个有序映射。映射是一种把 values 关联到 keys 的类型。此类型针对多种不同用途进行了优化; 它可以被视为数组、列表(向量)、哈希表(映射的实现)、字典、集合、堆栈、队列等等。 由于 array 的值可以是其它 array 所以树形结构和多维 array 也是允许的
顾名思义,链表像锁链一样。通过指针将一组零散的内存块串联起来,内存块称为链表的结点,结点除了存储数据之外还需要存储下一个结点内存地址,记录下一个结点地址的指针叫做后继指针next。第一个结点叫头结点,最有一个结点尾结点,头结点记录链表基地址,可以通过它遍历整个链表。
单链表 尾结点指向一个空地址NULL,表示这是链表的最后一个结点。单链表示意图
循环链表 特殊的单链表,尾结点指向头结点 循环链表示意图 优点从链尾到链头比较方便,适合处理环形数据,如约瑟夫问题
双向链表 支持两个方向,每个结点有两个指针,一个前继指针prev指向前面的结点,一个后继指针next指向后面的结点。占用内存比单链表多,效率比单链高。空间换时间 双向链表示意图
跳表 教程 示意图 一个单链表来讲,即便链表中存储的数据是有序的,查找效率就会很低。时间复杂度会很高,是 O(n)。每两个结点提取一个结点到上一级,我们把抽出来的那一级叫做索引或索引层。加来一层索引之后,查找一个结点需要遍历的结点个数减少了,也就是说查找效率提高了。这种链表加多级索引的结构,就是跳表。
随机访问复杂度 O(n), 插入删除复杂度 O(1)
应用
LRU 缓存淘汰算法
缓存淘汰策略 先进先出策略 FIFO(First In,First Out),最少使用策略 LFU(Least Frequently Used),
redis有序集合使用跳表实现
生活中的比喻就是一摞叠在一起的盘子,只能从上边拿。只能从一个方向(栈顶)操作,后进者先出,先进者后出,这就是典型的“栈”结构。是一种操作受限线性表。主要包含两个操作入栈,出栈,在栈顶插入一个数据和从栈顶删除一个数据。栈示意图
用数组实现的栈,我们叫作顺序栈,链表实现的栈,叫作链式栈
应用
当某个数据集合只涉及在一端插入和删除数据,并且满足后进先出,先进后出的特性,这时我们就应该首选栈。
函数调用栈,操作系统给每个线程分配了一块独立的内存空间,这块内存被组织成“栈”这种结构, 用来存储函数调用时的临时变量。每进入一个函数,就会将临时变量作为一个栈帧入栈,当被调用函数执行完成,返回之后,将这个函数对应的栈帧出栈。函数栈调用示意图
利用栈实现浏览器的前进,后退功能。示意图 TODO 后续补充代码示例。
编译器利用栈来实现,表达式求值,详情看教程。
栈在括号匹配中的应用,参考案例 结合正则表达式验证数学公式(含变量,js版)
把它想象成排队买票,先来的先买,后来的人只能站末尾,不允许插队。是一种操作受限的线性表数据结构 队列和栈对比示意图
先进者先出,这就是典型的“队列”,基本的操作:入队 enqueue() 放一个数据到队列尾部 出队 dequeue() 从队列头部取一个元素。用数组实现的队列叫作顺序队列,链表实现的队列叫作链式队列
PHP中SPL扩展只有双向链表实现的队列数据结构
循环队列 首尾相连形成环状,避免了数组结构的数据搬移操作 示意图
阻塞队列 增加了阻塞操作。在队列为空的时候,从队头取数据会被阻塞。因为此时还没有数据可取,直到队列中有了数据才能返回。如果队列已经满了,那么插入数据的操作就会被阻塞,直到队列中有空闲位置后再插入数据,然后再返回。示意图
php的案例,laravel框架的队列 和laravel horizon
并发队列 线程安全的队列,最简单直接的实现方式是直接在 enqueue()、dequeue() 方法上加锁,但是锁粒度大并发度会比较低,同一时刻仅允许一个存或者取操作。实际上,基于数组的循环队列,利用 CAS 原子操作(避免真正的去OS底层申请锁资源),可以实现非常高效的并发队列。这也是循环队列比链式队列应用更加广泛的原因
阻塞队列应用场景
基于阻塞队列实现的“生产者 – 消费者模型”,可以有效地协调生产和消费的速度。当“生产者”生产数据的速度过快,“消费者”来不及消费时,存储数据的队列很快就会满了。这个时候,生产者就阻塞等待,直到“消费者”消费了数据,“生产者”才会被唤醒继续“生产”。
可以通过协调“生产者”和“消费者”的个数,来提高数据的处理效率。比如前面的例子,我们可以多配置几个“消费者”,来应对一个“生产者” 。示意图
线程池(引申为有限资源池,可以是进程池或者协程,比如数据库连接池)没有空闲线程时,新的任务请求线程资源时,线程池该如何处理?各种处理策略又是如何实现的呢?
1.非阻塞的处理方式 直接拒绝任务请求
2.阻塞的处理方式,将请求排队,等到有空闲线程时,取出排队的请求继续处理。
链表实现无限排队的无界队列(unbounded queue),会导致过多的请求排队等待,请求处理的响应时间过长。对响应时间比较敏感的系统不适合链式队列
数组实现的有界队列(bounded queue),队列的大小有限,所以线程池中排队的请求超过队列大小时,接下来的请求就会被拒绝,对响应时间敏感的系统来说,就相对更加合理。注意问题,队列太大导致等待的请求太多,队列太小会导致无法充分利用系统资源、发挥最大性能
php-fpm进程池
数据之间不是简单的前后顺序
图解 图片地址
散列表用的是数组支持按照下标随机访问数据的特性,所以散列表其实就是数组的一种扩展,由数组演化而来。可以说,如果没有数组,就没有散列表。
散列表用的就是数组支持按照下标随机访问的时候,时间复杂度是 O(1) 的特性。我们通过散列函数把元素的键值映射为下标,然后将数据存储在数组中对应下标的位置。当我们按照键值查询元素时,我们用同样的散列函数,将键值转化数组下标,从对应的数组下标的位置取数据。示意图
散列函数, 用于计算hash(key) 的散列值。三点散列函数设计的基本要求
1.散列函数计算得到的散列值是一个非负整数;
2.如果 key1 = key2,那 hash(key1) == hash(key2);
3.如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2)
第一点数组下标是从 0 开始的,所以散列函数生成的散列值也要是非负整数。第二点相同的 key,经过散列函数得到的散列值也应该是相同的。第三点要想找到一个不同的 key 对应的散列值都不一样的散列函数,几乎是不可能的。像业界著名的MD5、SHA、CRC等哈希算法,也无法完全避免这种散列冲突。
递归是一种应用非常广泛的算法(或者编程技巧),表达力很强,写起来非常简洁。
应用案例
DFS 深度优先搜索 ,前中后序二叉树遍历,无限极分类
可以使用递归场景,需要满足的三个条件
1.一个问题的解可以分解为几个子问题的解
2.这个问题与分解之后的子问题,除了数据规模不同,求解思路完全一样
3. 存在递归终止条件。通俗的说法,递归入口和递归出口
如何编写递归代码
找到如何将大问题分解为小问题的规律,并且基于此写出递推公式,然后再推敲终止条件,最后将递推公式和终止条件翻译成代码。只要遇到递归,我们就把它抽象成一个递推公式,不用想一层层的调用关系,不要试图用人脑去分解递归的每个步骤
注意问题
要警惕堆栈溢出,函数调用会使用栈来保存临时变量。每调用一个函数,都会将临时变量封装为栈帧压入内存栈,等函数执行完成返回时,才出栈。系统栈或者虚拟机栈空间一般都不大。如果递归求解的数据规模很大,调用层次很深,一直压入栈,就会有堆栈溢出的风险。
PHP中要避免递归函数/方法调用超过 100-200 层,因为可能会使堆栈崩溃从而使当前脚本终止。 无限递归可视为编程错误。
警惕重复计算,通过一个数据结构(比如散列表或缓存)来保存已经求解过的数据
时间效率和空间利用,递归代码里多了很多函数调用,当这些函数调用的数量较大时,就会积聚成一个可观的时间成本。在空间复杂度上,因为递归调用一次就会在内存栈中保存一次现场数据,所以在分析递归代码空间复杂度时,需要额外考虑这部分的开销,比如我们前面讲到的电影院递归代码,空间复杂度并不是 O(1),而是 O(n)
将递归代码改写为非递归代码
用迭代循环替代
原地排序,就是特指空间复杂度是 O(1) 的排序算法
稳定性,这个概念是说,如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变
冒泡排序(Bubble Sort) 原地排序 稳定排序 最好O(n),最坏O(n2),平均O(n2) 教程
插入排序(Insertion Sort)原地排序 稳定排序 最好O(n),最坏O(n2),平均O(n2) 教程
选择排序(Selection Sort)原地排序 不稳定排序 最好O(n2),最坏O(n2),平均O(n2) 教程
归并排序(Merge Sort) 非原地排序 稳定排序 最好最坏平均O(nlogn) 教程
快速排序算法(Quicksort) 原地排序 不稳定排序 最好O(nlogn) 最坏O(n2) 平均O(nlogn) 教程
桶排序(Bucket sort) 非原地排序 稳定排序 O(n) 教程
计数排序(Counting sort)非原地排序 稳定排序 O(n+k) k是数据范围
基数排序(Radix sort) 原地排序 是稳定排序 O(dn) d是维度