只狼
analoganddigital / DQN_play_sekiro ricagj / train_your_own_game_AI
魂类游戏
超级玛丽
ppaquette / gym-super-mario vivek3141 / super-mario-neat
贪吃蛇
街头霸王二
DreamerV2
DreamerV2 的详细论文解读,可以看这个视频:
王者荣耀
FengQuanLi / ResnetGPT FengQuanLi / WZCQ
analoganddigital / DQN_play_sekiro ricagj / train_your_own_game_AI
ppaquette / gym-super-mario vivek3141 / super-mario-neat
DreamerV2 的详细论文解读,可以看这个视频:
FengQuanLi / ResnetGPT FengQuanLi / WZCQ
https://platform.openai.com/account/api-keys
https://yiyan.baidu.com/welcome
https://bard.google.com/?hl=en
https://5best1s.com/%E5%BC%80%E9%80%9A%E8%AE%A2%E9%98%85%E8%B4%AD%E4%B9%B0chatgpt-plus/
https://github.com/Helixform/CodeCursor vscode插件
https://github.com/josStorer/chatGPTBox
解决GPT报错,反复刷新页面,油猴脚本
https://gitee.com/ZnMaYun/happy-free-chat-gpt/
mac github.com/vincelwt/chatgpt-mac
app.pandagpt.io
另外一个利用AI来解读pdf文件的网站。和之前介绍的chatgpt不同的是可以对照pdf原文阅。不过实测速度较慢,而且点查找按钮会停止响应
https://github.com/chidiwilliams/buzz
可以在本地计算机上离线将音频转成文本,或者对视频生成字幕,基于OpenAI的Whisper模型。
主要功能包括:
* 从麦克风实时转录和翻译成文本
* 从音频和视频文件生成 TXT、SRT 和 VTT
* 支持 Whisper 、 Whisper.cpp 、与 Whisper 兼容的 Hugging Face 模型和 OpenAI Whisper API
* 适用于 Mac、Windows 和 Linux
怎么把一个超长内容喂给 ChatGPT,以 PDF 为例,以下都是纯 JS 开源工具推荐:
1. github.com/mozilla/pdf.js 能够比较好地解析 pdf 文件,但是解析出来可能是图片?看 2
2. github.com/naptha/tesseract.js 能够识别包括汉语等 100 种语言,拿到所有的文本,但内容分批可能出现错误截断?看 3
3. github.com/yanyiwu/nodejieba 结巴分词,避免将长内容分段的时候,错误截断短语或单词,完成了内容的分批之后看 4
4. github.com/openai/openai-node OpenAI 的 API 工具包,利用它将内容分批喂投给 ChatGPT
在将问题提交给 ChatGPT 之前,可以使用 embeddings 将问题与文档中的各个片段进行比较。基于余弦相似度或其他相似度度量,选择与问题最相关的片段进行处理。这样可以减少无关文本的干扰,提高 ChatGPT 回答问题的准确性。
:可以试试 chatdoc.com ,可以溯源,可以在PDF里选表格和文本针对性的提问
有人借助GPT-4,在没有JavaScript和3D游戏编程经验的情况下,一点点做除了一个 3D 太空赛跑游戏。最终效果看视频
twitter.com/ammaar/status/1637592014446551040
推荐视频:如何使用AI画图工具Midjourney生成Logo,很详细,尤其是如何借助prompt来生成想要的Logo
🔗 www.youtube.com/watch?v=HXh7b_ZND_M
https://www.ebaqdesign.com/blog/midjourney-logo-design?continueFlag=a9adaf9fc01778e2eb9d31292c8b63c9
https://gpt.level06.com/?continueFlag=a9adaf9fc01778e2eb9d31292c8b63c9
分享一个用GPT4查文献的方法。
之前大家都吐槽Chatgpt会给生成假文献,我也遇到过这个问题,就不用他查了。但是今天邻座韩国同学跟我说他最近一直用gpt查文献,他避免上述问题的方式就是加一个简单的限制:can be found on google scholar, with more than xxx citations
试了一下,挺管用的
推荐 GitHub 上一个开源项目:Shell GPT。
该工具直接在命令行中集成了 ChatGPT,通过它,可以帮助你快速编写 shell 命令、代码片段编写、Git 提交信息、文档、注释等内容。
用法主要有以下几种:
– 获取某个任务的执行指令;
– 直接转换时间、距离、重量、温度等单位;
– 在命令行终端搜索 shell 用法;
– 自动生成代码并存储;
– 在命令行跟 ChatGPT 对话,并迭代优化。
GitHub:github.com/TheR1D/shell_gpt
与其它 ChatGPT 应用一样,Shell GPT 在使用前,你需要先自行配置好 OpenAI API Key
https://learnprompting.org/zh-Hans/docs/intro
https://github.com/PlexPt/awesome-chatgpt-prompts-zh
什么是机器幻觉?
ChatGPT:机器幻觉是指由计算机程序或机器学习算法产生的虚假感知或错误结果。这些幻觉可能是由于算法中的缺陷、数据偏差或错误,或者是由于算法未能正确理解复杂的语境或情境。机器幻觉可能会导致错误的决策或预测,因此需要对算法进行不断的优化和调整以减少这种幻觉的出现。机器幻觉的研究也是人工智能领域中一个重要的课题,研究人员通过深入分析机器幻觉的原因和特征,努力提高机器学习算法的鲁棒性和智能性。
有什么方法可以帮我确认,你给我的答案不是机器幻觉?
ChatGPT:作为一名 AI 语言模型,我的回答是由预先训练好的算法生成的。虽然我的回答是基于已有的知识和经验,但是也无法保证完全没有机器幻觉的情况。为了确认我的回答,你可以采取以下方法:
请注意,我的回答是基于我所知道的信息和技能,可能存在不完善或错误的情况。因此,你需要对我的回答进行适当的评估和判断。

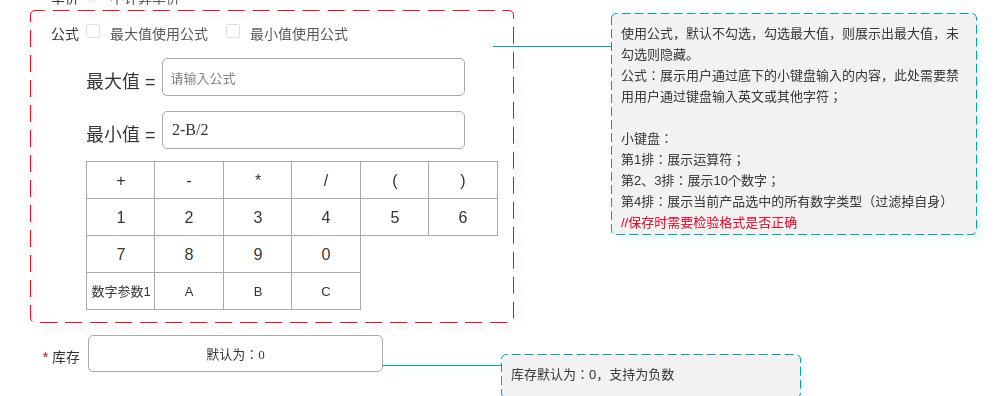
后台录入最小值,最大值公式,前台筛选时如果满足条件则进行公式计算
公式的CRUD
数据库保存公式时,公式中的参数用{参数id}替代,例如公式为P/1+2,P的id为5 则公式写作{5}/1+2
查询后将参数id替换成具体参数名,删除时,将包含{id}的公式字段清空
公式验证
验证公式时,先解析出{id}的参数,验证数据是否存在,然后在验证公式是否合法
/**
* 解析公式表达式中的参数
*
* @param string $formula 公式表达式
* @return mixed array|bool
*/
public function parseParamsIds(string $formula = '')
{
$value = $formula ? $formula : $this->formula_exp;
preg_match_all('/\{(\d+)\}/', $value, $matches);
if (! isset($matches[1]) || count($matches[1]) === 0) {
$this->error_message = '公式中缺少数字类型产品参数';
return false;
}
return $matches[1];
}
/**
* 公式验证
* @param string $formula_exp 公式表达式
* @param array $params 公式参数
* @return bool
*/
public function validateLegitimacy()
{
$formula_exp = trim($this->formula_exp);
//为空
if ($formula_exp === '') {
$this->error_message = '公式为空';
return false;
}
//错误情况,运算符连续
if (preg_match_all('/[\+\-\*\/]{2,}/', $formula_exp)) {
$this->error_message = '公式错误,运算符连续';
return false;
}
//空括号
if (preg_match_all('/\(\)/', $formula_exp)) {
$this->error_message = '公式错误,存在空括号';
return false;
}
//错误情况,(后面是运算符
if (preg_match_all('/\([\+\-\*\/]/', $formula_exp)) {
$this->error_message = '公式错误,(后面是运算符';
return false;
}
// 错误情况,)前面是运算符
if (preg_match_all('/[\+\-\*\/]\)/', $formula_exp)) {
$this->error_message = '公式错误,)前面是运算符';
return false;
}
//错误情况,(前面不是运算符
if (preg_match_all('/[^\+\-\*\/]\(/', $formula_exp)) {
$this->error_message = '公式错误,(前面不是运算符';
return false;
}
//错误情况,)后面不是运算符
if (preg_match_all('/\)[^\+\-\*\/]/', $formula_exp)) {
$this->error_message = '公式错误,)后面不是运算符';
return false;
}
//错误情况,使用除()+-*/之外的字符
if (preg_match_all('/[^\+\-\*\/0-9.a-zA-Z\(\)]/', $formula_exp)) {
$this->error_message = '公式错误,使用除()+-*/之外的字符';
return false;
}
//运算符号不能在首末位
if (preg_match_all('/^[\+\-\*\/.]|[\+\-\*\/.]$/', $formula_exp)) {
$this->error_message = '公式错误,运算符号不能在首末位';
return false;
}
//错误情况,括号不配对
$str_len = strlen($formula_exp);
$stack = [];
for ($i = 0; $i < $str_len; $i++) {
$item = $formula_exp[$i];
if ($item === '(') {
array_push($stack, $item);
} elseif ($item === ')') {
if (count($stack) > 0) {
array_pop($stack);
} else {
$this->error_message = '公式错误,括号不配对';
return false;
}
}
}
if (count($stack) > 0) {
$this->error_message = '公式错误,括号不配对';
return false;
}
//错误情况,变量没有来自“待选公式变量”
$arr = preg_split('/[\(\)\+\-\*\/]{1,}/', $formula_exp);
foreach ($arr as $key => $value) {
if (preg_match_all('/[A-Z]/i', $value) && ! isset($this->params[$value])) {
$this->error_message = '公式错误,参数不配';
return false;
}
}
return true;
}公式计算方案
1.逆波兰表达式也叫后缀表达
class FormulaCalculate
{
//正则表达式,用于将表达式字符串,解析为单独的运算符和操作项
public const PATTERN_EXP = '/((?:[a-zA-Z0-9_]+)|(?:[\(\)\+\-\*\/])){1}/';
public const EXP_PRIORITIES = ['+' => 1, '-' => 1, '*' => 2, '/' => 2, '(' => 0, ')' => 0];
/**
* 公式计算
*
* @param string $exp 普通表达式,例如 a+b*(c+d)
* @param array $exp_values 表达式对应数据内容,例如 ['a' => 1, 'b' => 2, 'c' => 3, 'd' => 4]
* @return int
*/
public static function calculate($exp, $exp_values)
{
$exp_arr = self::parseExp($exp); //将表达式字符串解析为列表
if (! is_array($exp_arr)) {
return 0;
}
$output_queue = self::nifix2rpn($exp_arr);
return self::calculateValue($output_queue, $exp_values);
}
/**
* 将字符串中每个操作项和预算符都解析出来
*
* @param string $exp 普通表达式
* @return mixed
*/
protected static function parseExp($exp)
{
$match = [];
preg_match_all(self::PATTERN_EXP, $exp, $match);
if ($match) {
return $match[0];
} else {
return null;
}
}
/**
* 将中缀表达式转为后缀表达式
*
* @param array $input_queue 输入队列
* @return array
*/
protected static function nifix2rpn($input_queue)
{
$exp_stack = [];
$output_queue = [];
foreach ($input_queue as $input) {
if (in_array($input, array_keys(self::EXP_PRIORITIES))) {
if ($input == '(') {
array_push($exp_stack, $input);
continue;
}
if ($input == ')') {
$tmp_exp = array_pop($exp_stack);
while ($tmp_exp && $tmp_exp != '(') {
array_push($output_queue, $tmp_exp);
$tmp_exp = array_pop($exp_stack);
}
continue;
}
foreach (array_reverse($exp_stack) as $exp) {
if (self::EXP_PRIORITIES[$input] <= self::EXP_PRIORITIES[$exp]) {
array_pop($exp_stack);
array_push($output_queue, $exp);
} else {
break;
}
}
array_push($exp_stack, $input);
} else {
array_push($output_queue, $input);
}
}
foreach (array_reverse($exp_stack) as $exp) {
array_push($output_queue, $exp);
}
return $output_queue;
}
/**
* 传入后缀表达式队列、各项对应值的数组,计算出结果
*
* @param array $output_queue 后缀表达式队列
* @param array $exp_values 表达式对应数据内容
* @return mixed
*/
protected static function calculateValue($output_queue, $exp_values)
{
$res_stack = [];
foreach ($output_queue as $out) {
if (in_array($out, array_keys(self::EXP_PRIORITIES))) {
$a = array_pop($res_stack);
$b = array_pop($res_stack);
switch ($out) {
case '+':
$res = $b + $a;
break;
case '-':
$res = $b - $a;
break;
case '*':
$res = $b * $a;
break;
case '/':
$res = $b / $a;
break;
}
array_push($res_stack, $res);
} else {
if (is_numeric($out)) {
array_push($res_stack, intval($out));
} else {
array_push($res_stack, $exp_values[$out]);
}
}
}
return count($res_stack) == 1 ? $res_stack[0] : null;
}
}
2.使用eval()运行代码,要注意代码安全性,做特别严格的验证
数据用例,前台输入值P 输入5 ,L输入6,
$eval = '$result = ';
//计算公式
$formula = '{P}/2+{L}*3+23';
//接收输入值
$params = ['{P}','{L}'];
$input = [5,6];
$eval .= str_replace($params, $input, $formula);
$eval .= ';';
eval($eval);
echo $result,PHP_EOL;3.两个堆栈,一个用来存储数字,一个用来存储运算符,遇到括号以后就递归进入括号内运算
参考
知识点导图 图片地址
m9rco/algorithm-php php实现算法
测试环境的硬件和数据规模会影响算法的测试结果,因此需要不用具体的测试数据测试,粗略的估计算法执行效率的方法(复杂度表示法)分为时间复杂度,空间复杂度
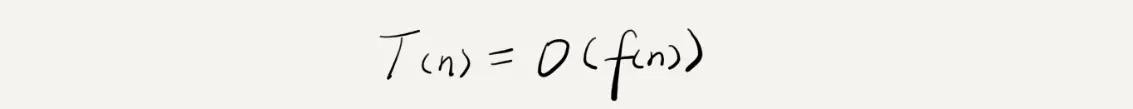
T(n) = O(f(n))
#渐进时间复杂度(时间复杂度)公式说明
T(n)所有代码的执行时间,n表示数据规模大小(循环处理次数),f(n)每行代码执行次数总和,f(n)是运算形式的表达式(例:(2n+2)),O表示代码执行时间T(n)和f(n)表达式成正比
公式表示代码执行时间随数据规模增长的变化趋势具体分析案例
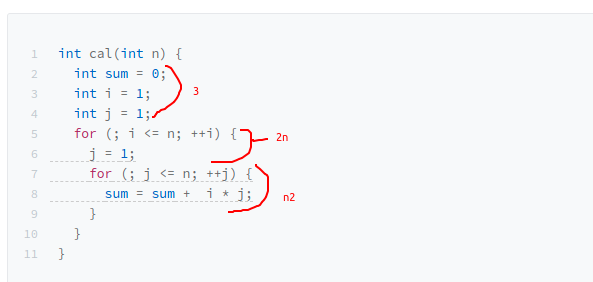
时间复杂度分析方法
1.只关注循环次数最多的一段代码
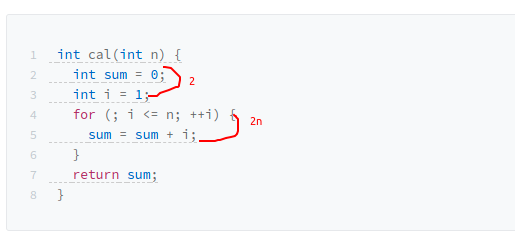
2.加法法则:总复杂度等于量级最大的那段代码的复杂度,因为数据规模参数只有n

3.乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
如果 T1(n)=O(f(n)),T2(n)=O(g(n));那么 T(n)=T1(n)T2(n)=O(f(n))O(g(n))=O(f(n)*g(n))
假设 T1(n) = O(n),T2(n) = O(n2),则 T1(n) * T2(n) = O(n3)
可以把乘法法则看成是嵌套循环
案例

常量阶O(1) ,代码的执行时间不随 n 的增大而增长,这样代码的时间复杂度我们都记作 O(1);一般情况下,只要算法中不存在循环语句、递归语句,即使有成千上万行的代码,其时间复杂度也是Ο(1)
对数阶O(logn) 、线性对数阶O(nlogon)
i=1; while (i <= n) { i = i * 2; }
//通过 2x=n 求解x,x=log2n 时间复杂度就是 O(log2n)。
i=1; while (i <= n) { i = i * 3; }
//通过 3x=n 求解x,x=log3n 时间复杂度就是 O(log3n)。变量 i 的值从 1 开始取,每循环一次就乘以 2。当大于 n 时,循环结束,变量 i 的取值就是一个等比数列
不管是以 2 为底、以 3 为底,还是以 10 为底,我们可以把所有对数阶的时间复杂度都记为 O(logn),对数之间是可以互相转换的,log3n 就等于 log32 * log2n,所以 O(log3n) = O(C * log2n),其中 C=log32 是一个常量。基于我们前面的一个理论:在采用大 O 标记复杂度的时候,可以忽略系数,即 O(Cf(n)) = O(f(n))。所以,O(log2n) 就等于 O(log3n)。因此,在对数阶时间复杂度的表示方法里,我们忽略对数的“底”,统一表示为 O(logn)
一段代码的时间复杂度是 O(logn),我们循环执行 n 遍,时间复杂度就是 O(nlogn) 了,O(nlogn) 也是一种非常常见的算法时间复杂度,如:归并排序、快速排序
线性阶O(n)
平方阶O(n2) 立方阶O(n3)…K次方阶O(nk)
O(m+n)、O(m*n)…

代码的复杂度由两(多个)个数据的规模决定,无法事先评估 m 和 n 谁的量级大,所以我们在表示复杂度的时候,就不能简单地利用加法法则,代码的时间复杂度就是 O(m+n)
时间复杂度为非多项式量级的算法问题叫作 NP(Non-Deterministic Polynomial,非确定多项式)问题
当数据规模 n 越来越大时,非多项式量级算法的执行时间会急剧增加,求解问题的执行时间会无限增长。所以,非多项式时间复杂度的算法其实是非常低效的算法,不常用
指数阶O(2n)
阶乘阶O(n!)
渐进空间复杂度(asymptotic space complexity),表示算法的存储空间与数据规模之间的增长关系
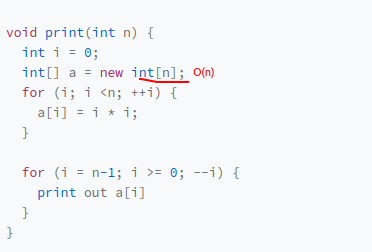
常见的空间复杂度就是 O(1)、O(n)、O(n2 ),像 O(logn)、O(nlogn) 这样的对数阶复杂度平时都用不到
狭义,数据结构是计算机中组织和存储数据的方式,是计算机科学中的理论体系。维基百科
广义,编程语言基于数据结构理论,实现了各自的数据结构,他们之间存在差异。数据结构和算法先于编程语言出现。编程语言中是一些数据类型,并不能跟数据结构和算法书籍中讲到的经典数据结构,完全一一对应。
举例说明:
c/c++中的数组是标准的数据结构
php中的数组是数据类型,底层实现是散列表(Hash Table)
直线型数据结构,数据排成像一条线,线性表上的数据最多只有前和后两个方向。
扩展阅读什么是线性表
用一组连续的内存空间,存储相同数据类型的数据;
支持使用下标随机访问数据,根据下标随机访问的时间复杂度为 O(1)
为了保持内存的数据连续性导致插入,删除两个操作比较低效O(n);标记删除法,每次删除不真正的搬移数据,只是记录数据已删除,当数组没有更多内存空间存储数据时, 才真正触发搬移数据。
标记删除法思想的应用,在数据库删除数据的时候也可以借鉴,如果
C语言中访问不存在下标的数组,会出现访问越界问题,
PS:PHP中的数组
PHP 中的 array 实际上是一个有序映射。映射是一种把 values 关联到 keys 的类型。此类型针对多种不同用途进行了优化; 它可以被视为数组、列表(向量)、哈希表(映射的实现)、字典、集合、堆栈、队列等等。 由于 array 的值可以是其它 array 所以树形结构和多维 array 也是允许的
顾名思义,链表像锁链一样。通过指针将一组零散的内存块串联起来,内存块称为链表的结点,结点除了存储数据之外还需要存储下一个结点内存地址,记录下一个结点地址的指针叫做后继指针next。第一个结点叫头结点,最有一个结点尾结点,头结点记录链表基地址,可以通过它遍历整个链表。
单链表 尾结点指向一个空地址NULL,表示这是链表的最后一个结点。单链表示意图
循环链表 特殊的单链表,尾结点指向头结点 循环链表示意图 优点从链尾到链头比较方便,适合处理环形数据,如约瑟夫问题
双向链表 支持两个方向,每个结点有两个指针,一个前继指针prev指向前面的结点,一个后继指针next指向后面的结点。占用内存比单链表多,效率比单链高。空间换时间 双向链表示意图
跳表 教程 示意图 一个单链表来讲,即便链表中存储的数据是有序的,查找效率就会很低。时间复杂度会很高,是 O(n)。每两个结点提取一个结点到上一级,我们把抽出来的那一级叫做索引或索引层。加来一层索引之后,查找一个结点需要遍历的结点个数减少了,也就是说查找效率提高了。这种链表加多级索引的结构,就是跳表。
随机访问复杂度 O(n), 插入删除复杂度 O(1)
应用
LRU 缓存淘汰算法
缓存淘汰策略 先进先出策略 FIFO(First In,First Out),最少使用策略 LFU(Least Frequently Used),
redis有序集合使用跳表实现
生活中的比喻就是一摞叠在一起的盘子,只能从上边拿。只能从一个方向(栈顶)操作,后进者先出,先进者后出,这就是典型的“栈”结构。是一种操作受限线性表。主要包含两个操作入栈,出栈,在栈顶插入一个数据和从栈顶删除一个数据。栈示意图
用数组实现的栈,我们叫作顺序栈,链表实现的栈,叫作链式栈
应用
当某个数据集合只涉及在一端插入和删除数据,并且满足后进先出,先进后出的特性,这时我们就应该首选栈。
函数调用栈,操作系统给每个线程分配了一块独立的内存空间,这块内存被组织成“栈”这种结构, 用来存储函数调用时的临时变量。每进入一个函数,就会将临时变量作为一个栈帧入栈,当被调用函数执行完成,返回之后,将这个函数对应的栈帧出栈。函数栈调用示意图
利用栈实现浏览器的前进,后退功能。示意图 TODO 后续补充代码示例。
编译器利用栈来实现,表达式求值,详情看教程。
栈在括号匹配中的应用,参考案例 结合正则表达式验证数学公式(含变量,js版)
把它想象成排队买票,先来的先买,后来的人只能站末尾,不允许插队。是一种操作受限的线性表数据结构 队列和栈对比示意图
先进者先出,这就是典型的“队列”,基本的操作:入队 enqueue() 放一个数据到队列尾部 出队 dequeue() 从队列头部取一个元素。用数组实现的队列叫作顺序队列,链表实现的队列叫作链式队列
PHP中SPL扩展只有双向链表实现的队列数据结构
循环队列 首尾相连形成环状,避免了数组结构的数据搬移操作 示意图
阻塞队列 增加了阻塞操作。在队列为空的时候,从队头取数据会被阻塞。因为此时还没有数据可取,直到队列中有了数据才能返回。如果队列已经满了,那么插入数据的操作就会被阻塞,直到队列中有空闲位置后再插入数据,然后再返回。示意图
php的案例,laravel框架的队列 和laravel horizon
并发队列 线程安全的队列,最简单直接的实现方式是直接在 enqueue()、dequeue() 方法上加锁,但是锁粒度大并发度会比较低,同一时刻仅允许一个存或者取操作。实际上,基于数组的循环队列,利用 CAS 原子操作(避免真正的去OS底层申请锁资源),可以实现非常高效的并发队列。这也是循环队列比链式队列应用更加广泛的原因
阻塞队列应用场景
基于阻塞队列实现的“生产者 – 消费者模型”,可以有效地协调生产和消费的速度。当“生产者”生产数据的速度过快,“消费者”来不及消费时,存储数据的队列很快就会满了。这个时候,生产者就阻塞等待,直到“消费者”消费了数据,“生产者”才会被唤醒继续“生产”。
可以通过协调“生产者”和“消费者”的个数,来提高数据的处理效率。比如前面的例子,我们可以多配置几个“消费者”,来应对一个“生产者” 。示意图
线程池(引申为有限资源池,可以是进程池或者协程,比如数据库连接池)没有空闲线程时,新的任务请求线程资源时,线程池该如何处理?各种处理策略又是如何实现的呢?
1.非阻塞的处理方式 直接拒绝任务请求
2.阻塞的处理方式,将请求排队,等到有空闲线程时,取出排队的请求继续处理。
链表实现无限排队的无界队列(unbounded queue),会导致过多的请求排队等待,请求处理的响应时间过长。对响应时间比较敏感的系统不适合链式队列
数组实现的有界队列(bounded queue),队列的大小有限,所以线程池中排队的请求超过队列大小时,接下来的请求就会被拒绝,对响应时间敏感的系统来说,就相对更加合理。注意问题,队列太大导致等待的请求太多,队列太小会导致无法充分利用系统资源、发挥最大性能
php-fpm进程池
数据之间不是简单的前后顺序
图解 图片地址
散列表用的是数组支持按照下标随机访问数据的特性,所以散列表其实就是数组的一种扩展,由数组演化而来。可以说,如果没有数组,就没有散列表。
散列表用的就是数组支持按照下标随机访问的时候,时间复杂度是 O(1) 的特性。我们通过散列函数把元素的键值映射为下标,然后将数据存储在数组中对应下标的位置。当我们按照键值查询元素时,我们用同样的散列函数,将键值转化数组下标,从对应的数组下标的位置取数据。示意图
散列函数, 用于计算hash(key) 的散列值。三点散列函数设计的基本要求
1.散列函数计算得到的散列值是一个非负整数;
2.如果 key1 = key2,那 hash(key1) == hash(key2);
3.如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2)
第一点数组下标是从 0 开始的,所以散列函数生成的散列值也要是非负整数。第二点相同的 key,经过散列函数得到的散列值也应该是相同的。第三点要想找到一个不同的 key 对应的散列值都不一样的散列函数,几乎是不可能的。像业界著名的MD5、SHA、CRC等哈希算法,也无法完全避免这种散列冲突。
递归是一种应用非常广泛的算法(或者编程技巧),表达力很强,写起来非常简洁。
应用案例
DFS 深度优先搜索 ,前中后序二叉树遍历,无限极分类
可以使用递归场景,需要满足的三个条件
1.一个问题的解可以分解为几个子问题的解
2.这个问题与分解之后的子问题,除了数据规模不同,求解思路完全一样
3. 存在递归终止条件。通俗的说法,递归入口和递归出口
如何编写递归代码
找到如何将大问题分解为小问题的规律,并且基于此写出递推公式,然后再推敲终止条件,最后将递推公式和终止条件翻译成代码。只要遇到递归,我们就把它抽象成一个递推公式,不用想一层层的调用关系,不要试图用人脑去分解递归的每个步骤
注意问题
要警惕堆栈溢出,函数调用会使用栈来保存临时变量。每调用一个函数,都会将临时变量封装为栈帧压入内存栈,等函数执行完成返回时,才出栈。系统栈或者虚拟机栈空间一般都不大。如果递归求解的数据规模很大,调用层次很深,一直压入栈,就会有堆栈溢出的风险。
PHP中要避免递归函数/方法调用超过 100-200 层,因为可能会使堆栈崩溃从而使当前脚本终止。 无限递归可视为编程错误。
警惕重复计算,通过一个数据结构(比如散列表或缓存)来保存已经求解过的数据
时间效率和空间利用,递归代码里多了很多函数调用,当这些函数调用的数量较大时,就会积聚成一个可观的时间成本。在空间复杂度上,因为递归调用一次就会在内存栈中保存一次现场数据,所以在分析递归代码空间复杂度时,需要额外考虑这部分的开销,比如我们前面讲到的电影院递归代码,空间复杂度并不是 O(1),而是 O(n)
将递归代码改写为非递归代码
用迭代循环替代
原地排序,就是特指空间复杂度是 O(1) 的排序算法
稳定性,这个概念是说,如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变
冒泡排序(Bubble Sort) 原地排序 稳定排序 最好O(n),最坏O(n2),平均O(n2) 教程
插入排序(Insertion Sort)原地排序 稳定排序 最好O(n),最坏O(n2),平均O(n2) 教程
选择排序(Selection Sort)原地排序 不稳定排序 最好O(n2),最坏O(n2),平均O(n2) 教程
归并排序(Merge Sort) 非原地排序 稳定排序 最好最坏平均O(nlogn) 教程
快速排序算法(Quicksort) 原地排序 不稳定排序 最好O(nlogn) 最坏O(n2) 平均O(nlogn) 教程
桶排序(Bucket sort) 非原地排序 稳定排序 O(n) 教程
计数排序(Counting sort)非原地排序 稳定排序 O(n+k) k是数据范围
基数排序(Radix sort) 原地排序 是稳定排序 O(dn) d是维度