为什么需要编译 ?我们平常写的高级语言和汇编语言是个人看的CPU无法直接运行,需要编译成机器码给CPU执行。
从软件工程师的角度来讲,CPU 就是一个执行各种计算机指令(Instruction Code)的逻辑机器。这里的计算机指令,就好比一门 CPU 能够听得懂的语言,我们也可以把它叫作机器语言(Machine Language)。
不同的 CPU 能够听懂的语言不太一样。比如,我们的个人电脑用的是 Intel 的 CPU,苹果手机用的是 ARM 的 CPU。这两者能听懂的语言就不太一样。类似这样两种 CPU 各自支持的语言,就是两组不同的计算机指令集 ,英文叫 Instruction Set。这里面的“Set”,其实就是数学上的集合,代表不同的单词、语法。
复杂指令集计算机 包含许多应用程序中很少使用的特定指令,由此产生的缺陷是指令长度不固定。
目前x86 架构微处理器如Intel 的Pentium /Celeron /Xeon 与AMD 的Athlon /Duron /Sempron ;以及其64位扩展系统的x86-64 架构的Intel 64的Intel Core /Core 2 /Celeron /Pentium /Xeon 与AMD64的Phenom II /Phenom /Athlon 64 /Athlon II /Opteron /AMD APU /Ryzen /EPYC 都属于复杂指令集。主要针对的操作系统是微软 的Windows 和苹果公司 的macOS 。另外Linux ,一些UNIX等,都可以运行在x86(复杂指令集)架构的微处理器。
精简指令集计算机 通过只执行在程序中经常使用的指令来简化处理器的结构,而特殊操作则以子程序的方式实现,它们的特殊使用通过处理器额外的执行时间来弥补。
这种指令集运算包括惠普的PA-RISC,国际商业机器 的PowerPC ,康柏 (后被惠普 收购)的Alpha,美普思科技 公司的MIPS,SUN公司的SPARC,ARM公司的ARM架构 等。目前有UNIX、Linux以及包括iOS、Android、Windows Phone等在内的大多数移动操作系统 运行在精简指令集的处理器上。
除了 C 这样的编译型的语言之外,不管是 Python 这样的解释型语言,还是 Java 这样使用虚拟机的语言,其实最终都是由不同形式的程序,把我们写好的代码,转换成 CPU 能够理解的机器码来执行的。只是解释型语言,是通过解释器在程序运行的时候逐句翻译,而 Java 这样使用虚拟机的语言,则是由虚拟机对编译出来的中间代码进行解释,或者即时编译成为机器码来最终执行。
为什么同一个程序,在同一台计算机上(可是我们的 CPU 并没有换掉 ,指令集是同一个),在 Linux 下可以运行,而在 Windows 下却不行呢?反过来,Windows 上的程序在 Linux 上也是一样不能执行的 ?
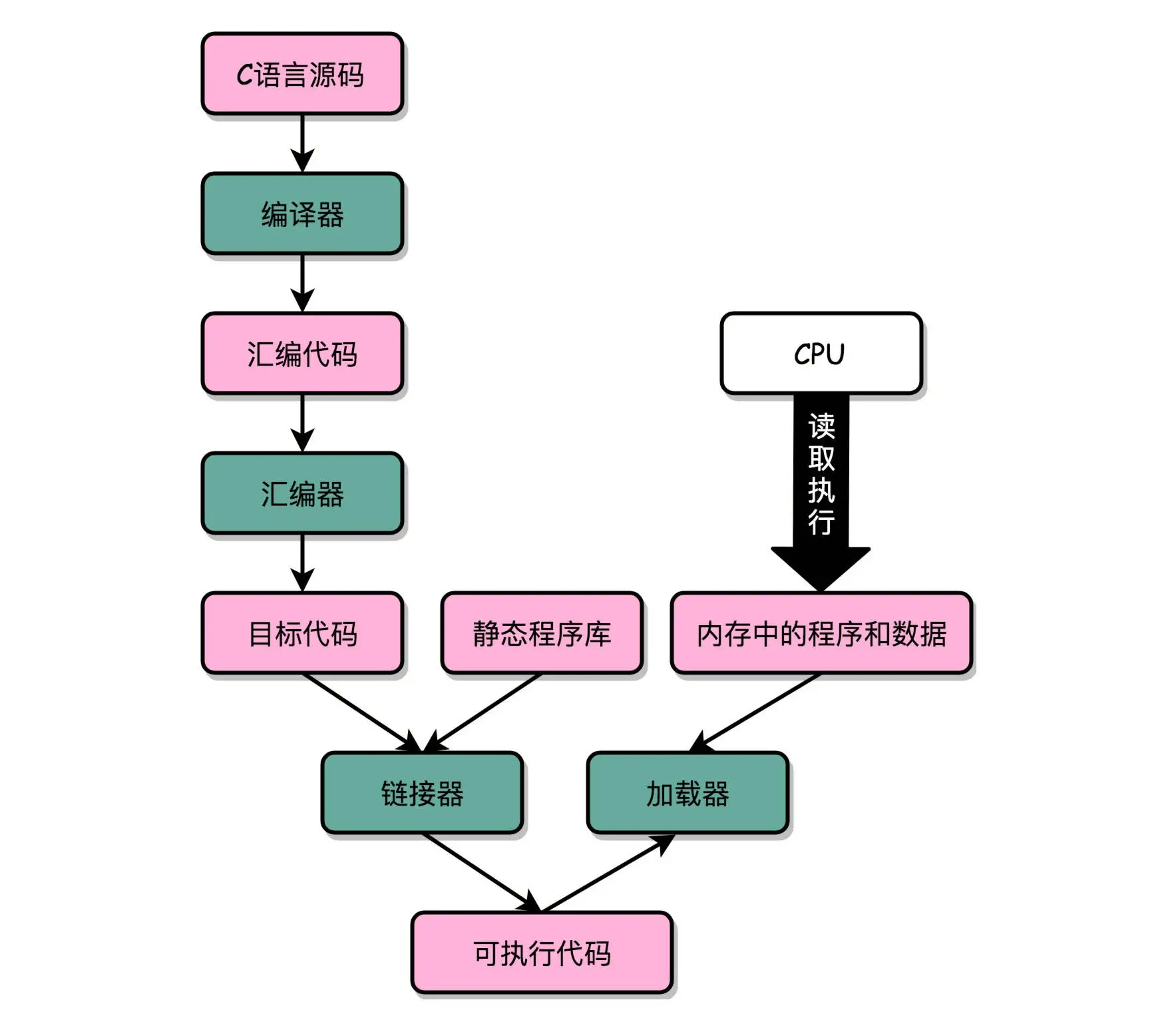
C 语言代码 – 汇编代码 – 机器码” 这个过程,在我们的计算机上进行的时候是由两部分组成的。
第一个部分由编译(Compile)、汇编(Assemble)以及链接(Link)三个阶段组成。在这三个阶段完成之后,我们就生成了一个可执行文件。
第二部分,我们通过装载器(Loader)把可执行文件装载(Load)到内存中。CPU 从内存中读取指令和数据,来开始真正执行程序。
在 Linux 下,可执行文件和目标文件所使用的都是一种叫 ELF(Execuatable and Linkable File Format)的文件格式,中文名字叫可执行与可链接文件格式,这里面不仅存放了编译成的汇编指令,还保留了很多别的数据,包含所有的代码,都存放在这个 ELF 格式文件里。这些名字和它们对应的地址,在 ELF 文件里面,存储在一个叫作符号表(Symbols Table)的位置里。符号表相当于一个地址簿,把名字和地址关联了起来
链接器会扫描所有输入的目标文件,然后把所有符号表里的信息收集起来,构成一个全局的符号表。然后再根据重定位表,把所有不确定要跳转地址的代码,根据符号表里面存储的地址,进行一次修正。最后,把所有的目标文件的对应段进行一次合并,变成了最终的可执行代码。这也是为什么,可执行文件里面的函数调用的地址都是正确的。
在链接器把程序变成可执行文件之后,要装载器去执行程序就容易多了。装载器不再需要考虑地址跳转的问题,只需要解析 ELF 文件,把对应的指令和数据,加载到内存里面供 CPU 执行就可以了。
Linux 下的 ELF 文件格式,而 Windows 的可执行文件格式是一种叫作 PE(Portable Executable Format)的文件格式。Linux 下的装载器只能解析 ELF 格式而不能解析 PE 格式。
Linux 下著名的开源项目 Wine,就是通过兼容 PE 格式的装载器,使得我们能直接在 Linux 下运行 Windows 程序的。而现在微软的 Windows 里面也提供了 WSL,也就是 Windows Subsystem for Linux,可以解析和加载 ELF 格式的文件。
推荐阅读想要更深入了解程序的链接过程和 ELF 格式,我推荐你阅读《程序员的自我修养——链接、装载和库》的 1~4 章。这是一本难得的讲解程序的链接、装载和运行的好书。
本地编译和交叉编译 本地编译可以理解为,在当前编译平台下,编译出来的程序只能放到当前平台下运行。平时我们常见的软件开发,都是属于本地编译:
比如,我们在 x86 平台上,编写程序并编译成可执行程序。这种方式下,我们使用 x86 平台上的工具,开发针对 x86 平台本身的可执行程序,这个编译过程称为本地编译。
交叉编译
比如,我们在 x86 平台上,编写程序并编译成能运行在 ARM 平台的程序,编译得到的程序在 x86 平台上是不能运行的,必须放到 ARM 平台上才能运行。
编译安装和软件包安装的区别 二级制安装包,是厂商预先在对应的cpu架构的电脑上编译好的二进制安装包,然后通过包管理工具分发,yum,rpm,apt,dpkg.优点是安装快。缺点是一些特殊的软件无法进行定制安装,目录和相关配置无法指定都是预先编译好的。
编译安装比较耗费时间,可以对模块进行定制,安装到指定目录。升级时需要重新编译
举例说明,比如php语言这种模块形式的服务软件,有很多扩展用不到,用软件包完全安装之后占用更多的系统资源,而有的第三方的模块,系统分发的软件包里没有,需要自己重新编译
动态库
从操作系统的角度来说,它仅仅提供最原始的系统调用是不够的,有很多业务逻辑的封装,在用户态来做更合适。但是,它也无法去穷举所有的编程语言,然后一一为它们开发各种语言的基础库。那怎么办?
聪明的操作系统设计者们想了一个好办法:动态库。几乎所有主流操作系统都有自己的动态库设计,包括:
Windows 的 dll(Dynamic Link Library);
Linux/Android 的 so(shared object);
Mac/iOS 的 dylib(Mach-O Dynamic Library)。
动态库本质上是实现了一个语言无关的代码复用机制。它是二进制级别的复用,而不是代码级别的。这很有用,大大降低了编程语言标准库的工作量。
动态库的原理其实很简单,核心考虑两个东西。
浮动地址。动态库本质上是在一个进程地址空间中动态加载程序片段,这个程序片段的地址显然在编译阶段是没法确定的,需要在加载动态库的过程把浮动地址固定下来。这块的技术非常成熟,我们在实模式下加载进程就已经在使用这样的技术了。
导出函数表。动态库需要记录有哪些函数被导出(export),这样用户就可以通过函数的名字来取得对应的函数地址。
有了动态库,编程语言的设计者实现其标准库来说就多了一个选择:直接调用动态库的函数并进行适度的语义包装。大部分语言会选择这条路,而不是直接用系统调用。
例如php的各种扩展,调用系统的动态库
程序运行是加载动态库的几种方法:
通过ldconfig命令
命令手册详细解释 演示案例
通过LD_LIBRARY_PATH环境变量
可以通过在.bashrc或者.cshrc中配置该环境变量,LD_LIBRARY_PATH的意思是告诉loader在哪些目录中可以找到共享库. 可以设置多个搜索目录, 这些目录之间用冒号分隔开.
通过编译选项-Wl
通过编译选项-Wl, -rpath指定动态搜索的路径
pkg-configpkg-config 是一个用于检索安装在Linux系统上的库文件信息和编译选项的工具。 而 pkgconfig 目录则是默认的包含了许多库文件信息和编译选项的目录之一。当我们想要使用被安装在系统上的某个库文件时,我们需要指定它的头文件路径、链接库路径和其他编译选项等信息,而这些信息通常会存储在 /usr/local/lib/pkgconfig/ 或者 /usr/lib/pkgconfig/(根据不同的发行版,目录可能有所不同)等目录下的对应库文件的 .pc 文件中。使用 pkg-config 工具可以方便地读取这些信息,并将它们传递给编译器来编译我们自己的程序,以便正确地链接和运行所需的库文件
在某些情况下,我们需要根据需要手动指定pkgconfig的目录
export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig/:$PKG_CONFIG_PATH常见的pkg config 目录,ubuntu系统
/usr/lib/pkgconfig
/usr/lib/x86_64-linux-gnu/pkgconfig
/usr/local/lib/pkgconfig
通俗易懂的讲解
编译器的工作过程——阮一峰
相关文章
软件的安装: 编译安装和包管理器安装有什么优势和劣势?
深入浅出计算机组成原理-05计算机指令集
ELF和静态链接:为什么程序无法同时在Linux和Windows下运行?
什么是交叉编译
操作系统内核与编程接口