Warning: require_once(ROOTPATHconfig/bluebee.inc.php): failed to open stream: No such file or directory in /web/code/mygym/mygym_pc/include/head.php on line 23
Fatal error: require_once(): Failed opening required 'ROOTPATHconfig/bluebee.inc.php' (include_path='.:/usr/local/php54/lib/php') in /web/code/mygym/mygym_pc/include/head.php on line 23
service mysqld status 显示启动失败,查看/var/log/mysqld.log 日志 报错如下
mysqld_safe mysqld from pid file /var/lib/mysql/mysqld.pid ended
/etc/my.cnf配置如下
# For advice on how to change settings please see
# http://dev.mysql.com/doc/refman/5.6/en/server-configuration-defaults.html
[mysqld]
skip-grant-tables
#
# Remove leading # and set to the amount of RAM for the most important data
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
# innodb_buffer_pool_size = 128M
#
# Remove leading # to turn on a very important data integrity option: logging
# changes to the binary log between backups.
# log_bin
#
# Remove leading # to set options mainly useful for reporting servers.
# The server defaults are faster for transactions and fast SELECTs.
# Adjust sizes as needed, experiment to find the optimal values.
# join_buffer_size = 128M
# sort_buffer_size = 2M
# read_rnd_buffer_size = 2M
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
# Recommended in standard MySQL setup
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
[mysqld_safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
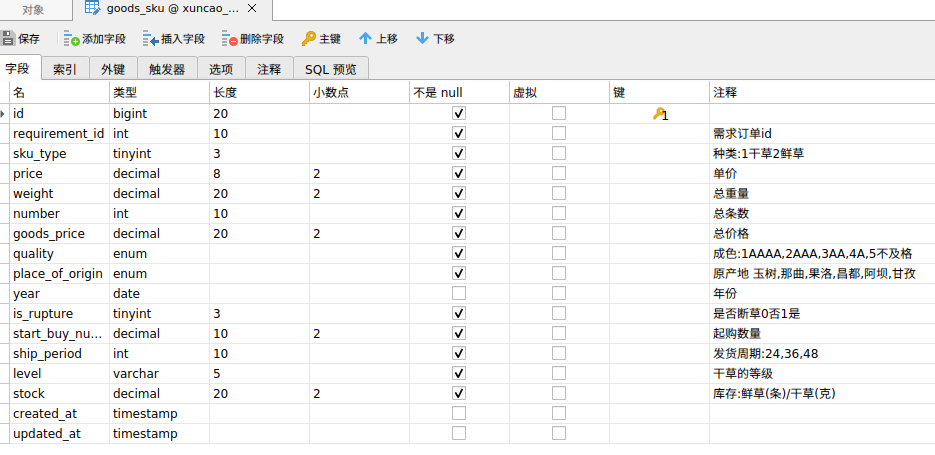
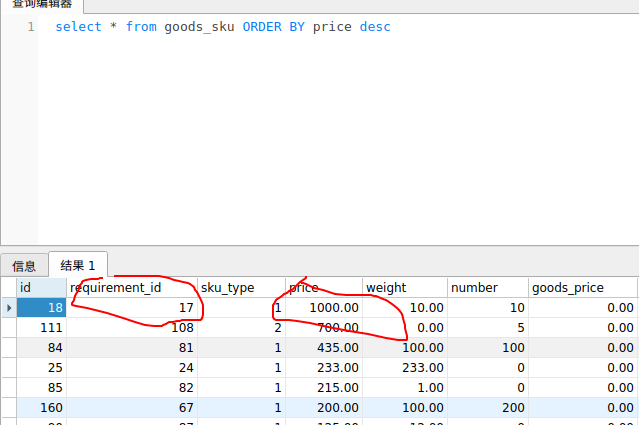
select * from requirement_order ORDER BY (select goods_sku.price from goods_sku where goods_sku.requirement_id = requirement_order.id limit 1) desc
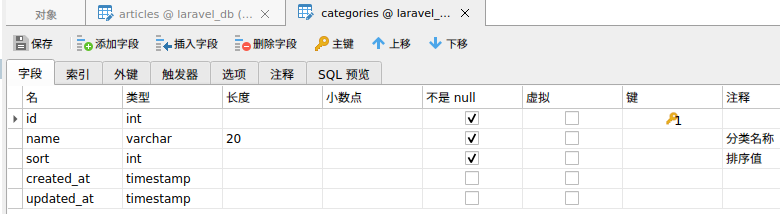
一对多限制从表条数查询,比如查出所有分类以及每个分类下n条文章
表结构如下
分类表文章表
方法一
laravel构造器写法
$category = Category::select('id', 'name')
->with([
'article'=>function ($query) {
$query->select('id', 'cat_id', 'title', 'author')
->whereRaw('(select count(*) from articles as articles2 where articles2.cat_id = articles.cat_id and articles2.id >= articles.id) <= ?', [3]);
}
])
->get();
代码执行SQL
//查询分类
select `id`,`name` from `categories`
//查询分类下文章,每个分类下3条
select
`id`,
`cat_id`,
`title`,
`author`
from
`articles`
where
`articles`.`cat_id` in (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
and (
select
count(*)
from
articles as articles2
where
articles2.cat_id = articles.cat_id
and articles2.id >= articles.id
) <= 3
mysql-workbench
Workbench can't find libproj.so, some options may be unavailable.
/usr/bin/mysql-workbench-bin: symbol lookup error: /usr/lib/mysql-workbench/libwbprivate.so.8.0.16: undefined symbol:
_ZN7pcrecpp2RE4InitEPKcPKNS_10RE_OptionsE