阅读原文 转自博客园 知行思新
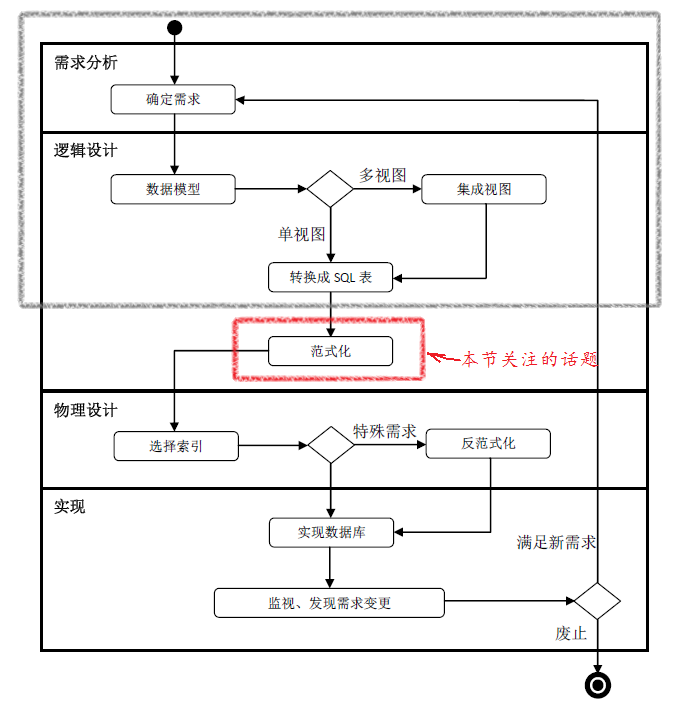
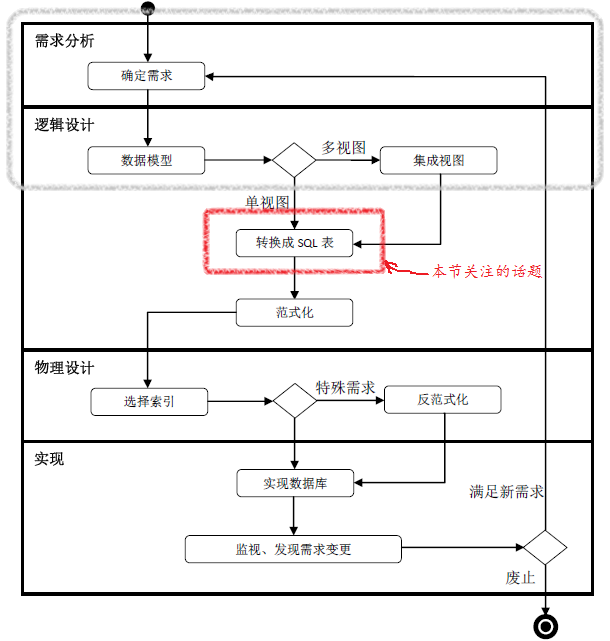
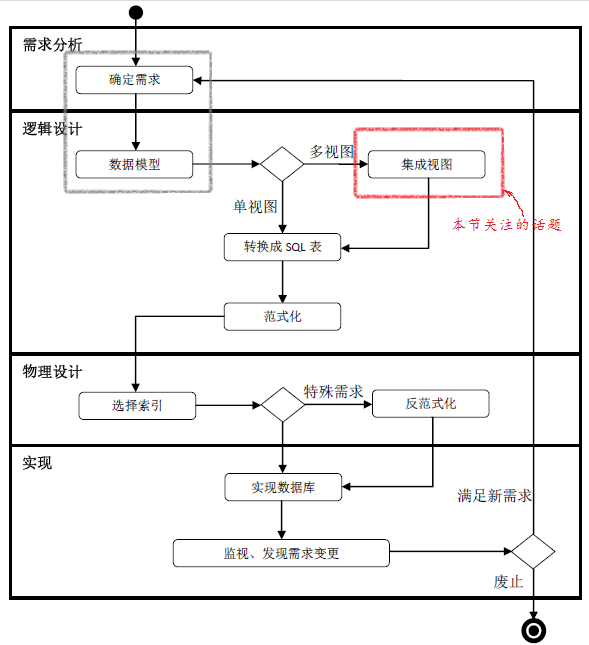
引言:前文(数据库设计 Step by Step (8)——视图集成 )讨论了如何把局部ER图集成为全局ER图。有了全局ER图后,我们就可以把ER图转化为关系数据库中的SQL表了。俯瞰整个数据库生命周期(如下图所示),找到我们的“坐标”。
把ER图转化为关系数据库中的表结构是一个非常自然的过程。许多ER建模工具除了辅助绘制ER图外,还能自动地把ER图转化为SQL表。
从ER模型到SQL表
从ER图转化得到关系数据库中的SQL表,一般可分为3类。
1. 转化得到的SQL表与原始实体包含相同信息内容。该类转化一般适用于:
二元“多对多”关系中,任何一端的实体
二元“一对多”关系中,“一”一端的实体
二元“一对一”关系中,某一端的实体
二元“多对多”回归关系中,任何一端的实体(注:关系两端都指向同一个实体)
三元或n元关系中,任何一端的实体
层次泛化关系中,超类实体
2. 转化得到的SQL表除了包含原始实体的信息内容之外,还包含原始实体父实体的外键。该类转化一般适用于:
二元“一对多”关系中,“多”一端的实体
二元“一对一”关系中,某一端的实体
二元“一对一”或“一对多”回归关系中,任何一端的实体
该转化是处理关系的常用方法之一,即在子表中增加指向父表中主键的外键信息。
3. 由“关系”转化得到的SQL表,该表包含“关系”所涉及的所有实体的外键,以及该“关系”自身的属性信息。该类转化一般适用于:
二元“多对多”关系
二元“多对多”回归关系
三元或n元关系
该转化是另一种常用的关系处理方法。对于“多对多”关系需要定义为一张包含两个相关实体主键的独立表,该表还能包含关系的属性信息。
转化过程中对于NULL值的处理规则
1. 当实体之间的关系是可选的,SQL表中的外键列允许为NULL。
2. 当实体之间的关系是强制的,SQL表中的外键列不允许为NULL。
3. 由“多对多”关系转化得到的SQL表,其中的任意外键列都不允许为NULL。
一般二元关系的转化
1. “一对一”,两实体都为强制存在
当两个实体都是强制存在的(如图1所示),每一个实体都对应转化为一张SQL表,并选择两个实体中任意一个作为主表,把它的主键放入另一个实体对应的SQL表中作为外键,该表称为从表。
图1表示的语义为:每一张报表都有一个缩写,每一缩写只代表一张报表。转化得到的SQL表定义如下:
注:本节中所有SQL代码在SQL Server 2008环境中测试通过。
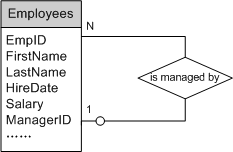
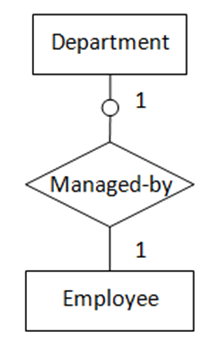
2. “一对一”,一实体可选存在,另一实体强制存在
当两个实体中有一个为“可选的”,则“可选的”实体对应的SQL表一般作为从表,包含指向另一实体的外键(如图2所示)
(图2 “一对一”,一实体可选存在,另一实体强制存在)
图2表示的语义为:每一个部门必须有一位经理,大部分员工不是经理,一名员工最多只能是一个部门的经理。转化得到的SQL表定义如下:
create table employee
(
emp_id char(10),
emp_name char(20),
primary key(emp_id)
);
create table department
(
dept_no integer,
dept_name char(20),
mgr_id char(10) not null unique,
primary key(dept_no),
foreign key(mgr_id) references employee
on update cascade
);另一种转化方式是把“可选的”实体作为主表,让“强制存在的”实体作为从表,包含外键指向“可选的”实体,这种方式外键列允许为NULL。以图2为例,可把实体Employee转化为从表,包含外键列dept_no指向实体Department,该外键列将允许为NULL。因为Employee的数量远大于Department的数量,故会占用更多的存储空间。
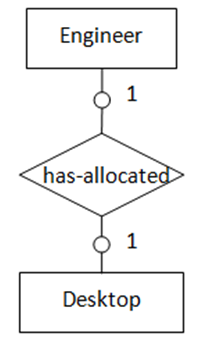
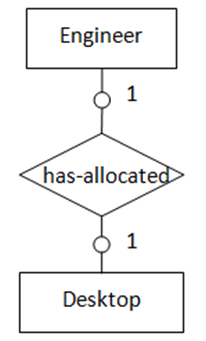
3. “一对一”,两实体都为可选存在
当两个实体都是可选的(如图3所示),可选任意一个实体包含外键指向另一实体,外键列允许为NULL值。
图3表示的语义为:部分台式电脑被分配给部分工程师,一台电脑只能分配给一名工程师,一名工程师最多只能分配到一台电脑。转化得到的SQL表定义如下:
create table engineer
(
emp_id char(10),
emp_name char(20),
primary key(emp_id)
);
create table desktop
(
desktop_no integer,
emp_id char(10),
primary key(desktop_no),
foreign key(emp_id) references engineer
on delete set null on update cascade
);4. “一对多”,两实体都为强制存在
在“一对多”关系中,无论“多”端是强制存在的还是可选存在的都不会影响其转化形式,外键必须出现在“多”端,即“多”端转化为从表。当“一”端实体是可选存在时,“多”端实体表中的外键列允许为NULL。
图4表示的语义为:每名员工都属于一个部门,每个部门至少有一名员工。转化得到的SQL表定义如下:
create table department
(
dept_no integer,
dept_name char(20),
primary key(dept_no)
);
create table employee
(
emp_id char(10),
emp_name char(20),
dept_no integer not null,
primary key(emp_id),
foreign key(dept_no) references department
on update cascade
);5. “一对多”,一实体可选存在,另一实体强制存在
图5表示的语义为:每个部门至少发布一张报表,一张报表不一定由某个部门来发布。转化得到的SQL表定义如下:
create table department
(
dept_no integer,
dept_name char(20),
primary key(dept_no)
);
create table report
(
report_no integer,
dept_no integer,
primary key(report_no),
foreign key(dept_no) references department
on delete set null on update cascade
);
注:解释一下report表创建脚本的最后一行“on delete set null on update cascade”的用处。当没有这一行时,更新department表中dept_no字段会失败,删除department中记录也会失败,报出与外键约束冲突的提示。如果有了最后一行,更新department表中dept_no字段,report表中对应记录的dept_no也会同步更改,删除department中记录,会使report表中对应记录的dept_no值变为NULL。6. “多对多”,两实体都为可选存在
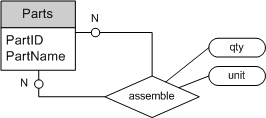
在“多对多”关系中,需要一张新关系表包含两个实体的主键。无论两边实体是否为可选存在的,其转化形式一致,关系表中的外键列不能为NULL。实体可选存在,在关系表中表现为是否存在对应记录,而与外键是否允许NULL值无关。
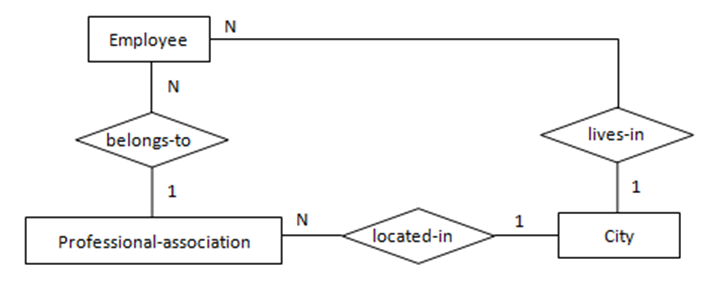
图6表示的语义为:一名工程师可能是专业协会的会员且可参加多个专业协会。每一个专业协会可能有多位工程师参加。转化得到的SQL表定义如下:
create table engineer
(
emp_id char(10),
primary key(emp_id)
);
create table prof_assoc
(
assoc_name varchar(256),
primary key(assoc_name)
);
create table belongs_to
(
emp_id char(10),
assoc_name varchar(256),
primary key(emp_id, assoc_name),
foreign key(emp_id) references engineer
on delete cascade on update cascade,
foreign key(assoc_name) references prof_assoc
on delete cascade on update cascade
);二元回归关系的转化
对于“一对一”或“一对多”回归关系的转化都是在SQL表中增加一列与主键列类型、长度相同的外键列指向实体本身。外键列的命名需与主键列不同,表明其用意。外键列的约束根据语义进行确定。
7. “一对一”,两实体都为可选存在
(图7 “一对一”,两实体都为可选存在)
图7表示的语义为:公司员工之间可能存在夫妻关系。转化得到的SQL表定义如下:
create table employee
(
emp_id char(10),
emp_name char(20),
spouse_id char(10),
primary key(emp_id),
foreign key(spouse_id) references employee
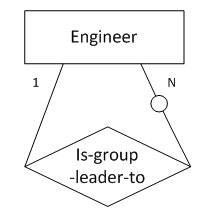
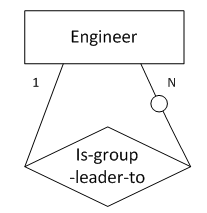
);8. “一对多”,“一”端为强制存在,“多”端为可选存在
图8表示的语义为:工程师被分为多个组,每个组有一名组长。
转化得到的SQL表定义如下:
create table engineer
“多对多”回归关系无论是可选存在的还是强制存在的都需新增一张关系表,表中的外键列须为NOT NULL。
9. “多对多”,两端都为可选存在
(图9 “多对多”,两端都为可选存在)
图9表示的语义为:社交网站中人之间的朋友关系,每个人都可能有很多朋友。转化得到的SQL表定义如下:
create table person
(
person_id char(10),
person_name char(20),
primary key(person_id)
);
create table friend
(
person_id char(10),
friend_id char(10),
primary key(person_id, friend_id),
foreign key(person_id) references person,
foreign key(friend_id) references person,
check(person_id < friend_id) );
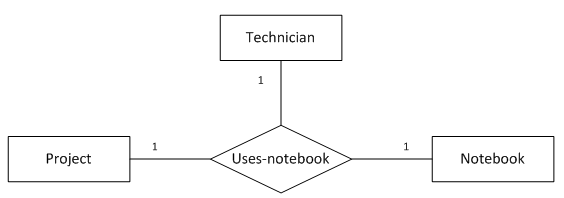
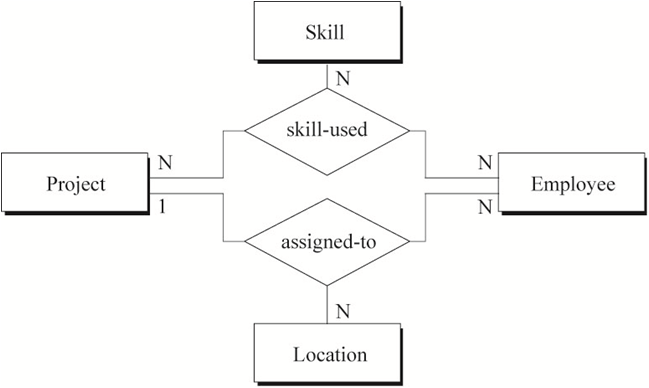
}三元和n元关系的转化 无论哪种形式的三元关系在转化时都会创建一张关系表包含所有实体的主键。三元关系中,“一”端实体的个数决定了函数依赖的数量。因此,“一对一对一”关系有三个函数依赖式,“一对一对多”关系有两个函数依赖式,“一对多对多”关系有一个函数依赖式。“多对多对多”关系的主键为所有外键的联合。 10. “一对一对一”三元关系
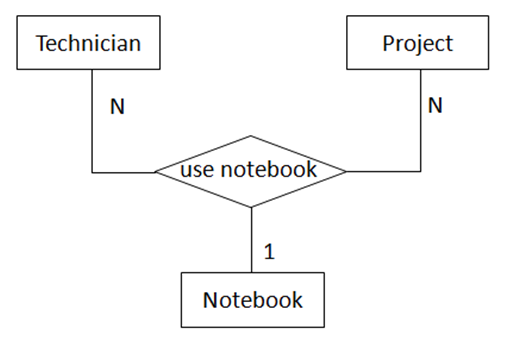
(图10 “一对一对一”三元关系)
图10表示的语义为:
create table technician (
emp_id char(10),
primary key(emp_id)
);
create table project (
project_name char(20),
primary key(project_name)
);
create table notebook (
notebook_no integer,
primary key(notebook_no)
);
create table uses_notebook (
emp_id char(10),
project_name char(20),
notebook_no integer not null,
primary key(emp_id, project_name),
foreign key(emp_id) references technician on delete cascade on update cascade,
foreign key(project_name) references project on delete cascade on update cascade,
foreign key(notebook_no) references notebook on delete cascade on update cascade,
unique(emp_id, notebook_no), unique(project_name, notebook_no)
);函数依赖
emp_id, project_name -> notebook_no
emp_id, notebook_no -> project_name
project_name, notebook_no -> emp_id
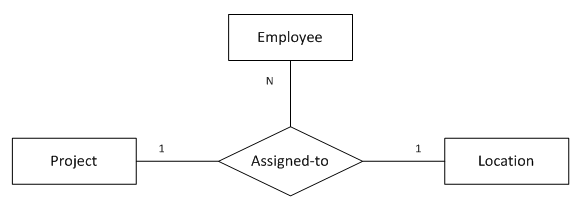
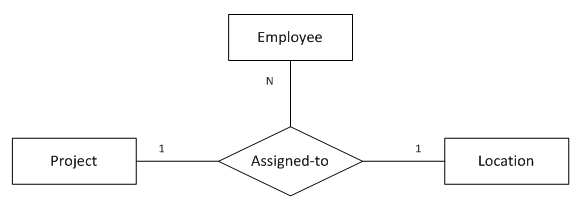
11. “一对一对多”三元关系
(图11 “一对一对多”三元关系)
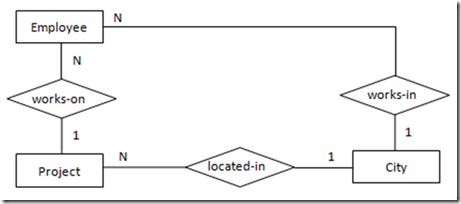
图11表示的语义为:
参与1个项目的1名员工只会在1个地点做该项目
1名员工在1个地点只能做1个项目
1个地点的1个项目可能有多名员工参与
注:1名员工可以在不同的地点做不同的项目
转化得到的SQL表定义如下:
create table employee
(
emp_id char(10),
emp_name char(20),
primary key(emp_id)
);
create table project
(
project_name char(20),
primary key(project_name)
);
create table location
(
loc_name char(15),
primary key(loc_name)
);
create table assigned_to
(
emp_id char(10),
project_name char(20),
loc_name char(15) not null,
primary key(emp_id, project_name),
foreign key(emp_id) references employee
on delete cascade on update cascade,
foreign key(project_name) references project
on delete cascade on update cascade,
foreign key(loc_name) references location
on delete cascade on update cascade,
unique(emp_id, loc_name)
);函数依赖:
emp_id, project_name -> loc_name
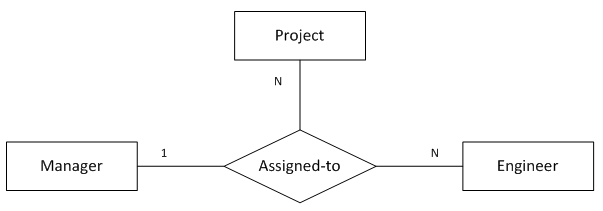
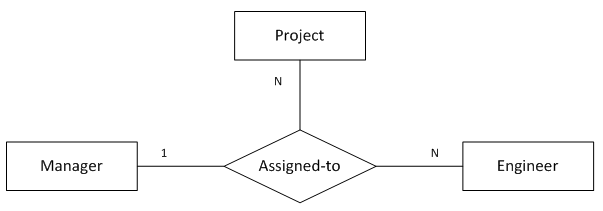
12. “一对多对多”三元关系
(图12 “一对多对多”三元关系)
图12表示的语义为:
1个项目中的1名工程师只会有1名经理
1个项目中的1名经理会带领多名工程师做该项目
1名经理和他手下的1名工程师可能参与多个项目
转化得到的SQL表定义如下:
create table project
(
project_name char(20),
primary key(project_name)
);
create table manager
(
mgr_id char(10),
primary key(mgr_id)
);
create table engineer
(
emp_id char(10),
primary key(emp_id)
);
create table manages
(
project_name char(20),
mgr_id char(10) not null,
emp_id char(10),
primary key(project_name, emp_id),
foreign key(project_name) references project
on delete cascade on update cascade,
foreign key(mgr_id) references manager
on delete cascade on update cascade,
foreign key(emp_id) references engineer
on delete cascade on update cascade
);函数依赖:
project_name, emp_id -> mgr_id
13. “多对多对多”三元关系
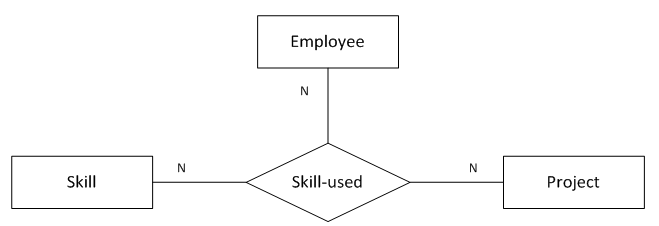
(图13 “多对多对多”三元关系)
图13表示的语义为:
1名员工在1个项目中可以运用多种技能
1名员工的1项技能可以在多个项目中运用
1个项目中的1项技能可以被参与该项目的多名员工运用
转化得到的SQL表定义如下:
create table employee
(
emp_id char(10),
emp_name char(20),
primary key(emp_id)
);
create table skill
(
skill_type char(15),
primary key(skill_type)
);
create table project
(
project_name char(20),
primary key(project_name)
);
create table sill_used
(
emp_id char(10),
skill_type char(15),
project_name char(20),
primary key(emp_id, skill_type, project_name),
foreign key(emp_id) references employee
on delete cascade on update cascade,
foreign key(skill_type) references skill
on delete cascade on update cascade,
foreign key(project_name) references project
on delete cascade on update cascade
);函数依赖:
无
泛化与聚合
泛化抽象结构中的超类实体和各子类实体分别转化为对应的SQL表。超类实体转化得到的表包含超类实体的键和所有公共属性。子类实体转化得到的表包含超类实体的键和子类实体特有的属性。
要保证泛化层次中数据的完整性就必须保证某些操作在超类表和子类表的之间的同步。若超类表的主键需做更新,则子类表中对应记录的外键必须一起更新。若需删除超类表中的记录,子类表中对应记录也需一起删除。我们可以在定义子类表时加入外键级联约束。这一规则对于覆盖与非覆盖的子类泛化都适用。
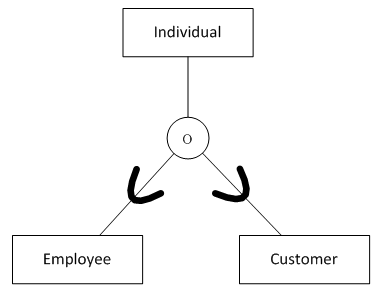
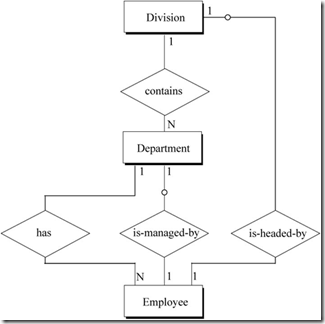
14. 泛化层次关系
(图14 泛化层次关系)
图14表示的语义为:
个人可能是一名员工,或是一位顾客,或同时是员工与顾客,或两者都不是
转化得到的SQL表定义如下:
create table individual
(
indiv_id char(10),
indiv_name char(20),
indiv_addr char(20),
primary key(indiv_id)
);
create table employee
(
emp_id char(10),
job_title char(15),
primary key(emp_id),
foreign key(emp_id) references individual
on delete cascade on update cascade
);
create table customer
(
cust_no char(10),
cust_credit char(12),
primary key(cust_no),
foreign key(cust_no) references individual
on delete cascade on update cascade
);有些数据库开发者还会在超类表中增加一个鉴别属性。鉴别属性对于每一种子类有不同的值,表示从哪一个子类中能获得进一步的信息。
聚合抽象的转化方式也是为超类实体和每一个子类实体生成SQL表,但聚合中的超类与子类没有公共属性和完整性约束。聚合的主要功能是提供一种抽象来辅助视图集成的过程。
转化步骤
以下总结了从ER图到SQL表的基本转化步骤
1. 把每一个实体转化为一张表,其中包含键和非键属性。
2. 把每一个“多对多”二元或二元回归关系转化为一张表,其中包含实体的键和关系的属性。
3. 把三元及更高元(n元)关系转化为一张表。
让我们一一对这三个步骤进行讨论。
实体转化
若两个实体之间是“一对多”关系,把“一”端实体的主键加入到“多”端实体表中作为外键。若两实体间是“一对一”关系,把某个“一”端实体的主键放入另一实体表中作为外键,加入外键的实体理论上可以任选,但一般会遵循如下原则:按照实体间最为自然的父子关系,把父实体的键放入子实体中;另一种策略是基于效率,把外键加入到具有较少行的表中。
把泛化层次中的每一个实体转化为一张表。每张表都会包含超类实体的键。事实上子类实体的主键同时也是外键。超类表中还包含所有相关实体的公共非键属性,其他表包含每一子类实体特有的非键属性。
转化得到的SQL表可能会包含not null, unique, foreign key等约束。每一张表必须有一个主键(primary key),主键隐含着not null和unique约束。
“多对多”二元关系转化
每一个“多对多”二元关系能转化为一张表,包含两个实体的键和关系的属性。
这一转化得到的SQL表可能包含not null约束。在这里没有使用unique约束的原因是关系表的主键是由各实体的外键复合组成的,unique约束已隐含。
三元关系转化
每一个三元(或n元)关系转化为一张表,包含相关实体的n个主键以及该关系的属性。
这一转化得到的表必须包含not null约束。关系表的主键由各实体的外键复合组成。n元关系表具有n个外键。除主键约束外,其他候选键(candidate key)也应加上unique约束。
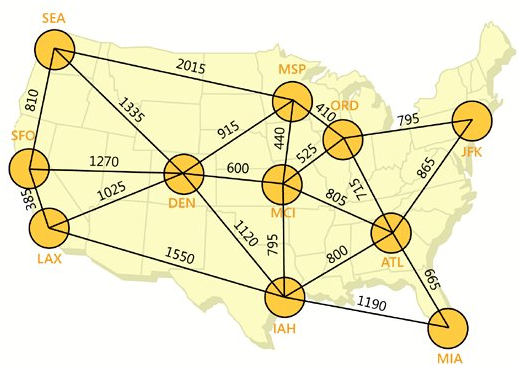
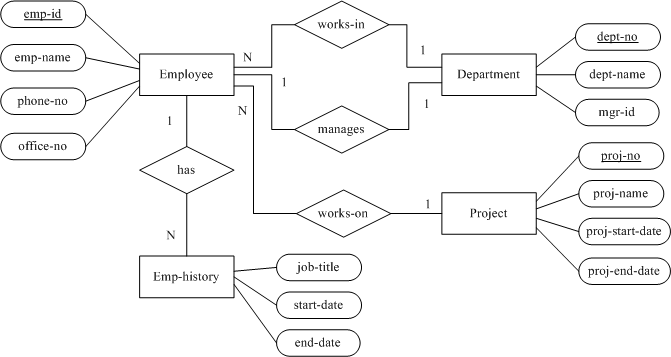
ER-to-SQL转化步骤示例
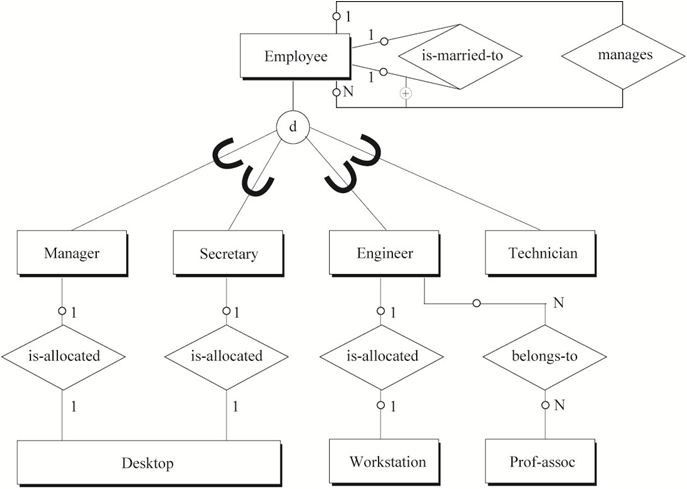
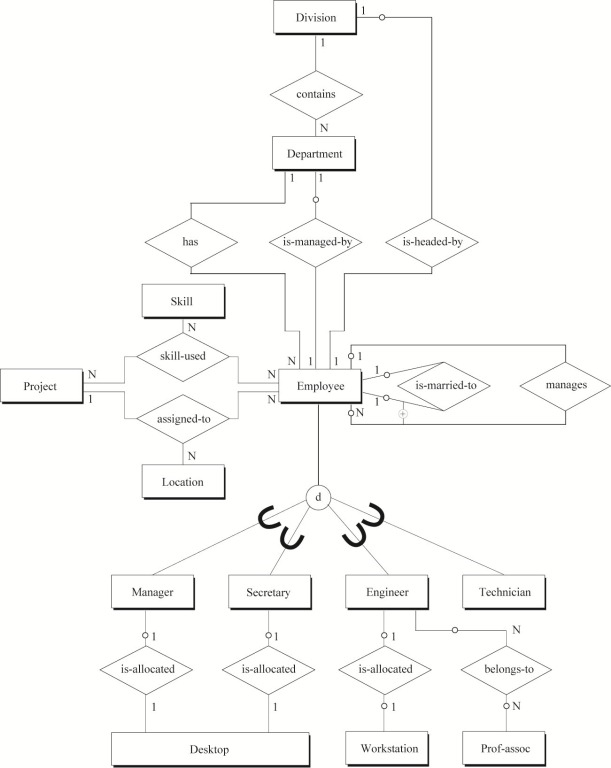
把数据库设计Step by Step (7)——概念数据建模中最后得到的公司人事和项目数据库的全局ER图(图9)转化为SQL表。
1. 直接由实体生成的SQL表有:
Division Department Employee Manager Secretary Engineer
Technician Skill Project Location Prof_assoc Desktop
Workstation
2. 由“多对多”二元关系及“多对多”二元回归关系生成的SQL表有:
belongs_to
3. 由三元关系生成的SQL表有:
skill_used assigned_to
总结与回顾
1. 通过一些简单的规则就能把ER模型中的实体、属性和关系转化为SQL表。
2. 实体在转化为表的过程中,其中的属性一一被映射为表的属性。
3. “一对一”或“一对多”关系中的“子”端实体转化成的SQL表必须包含另一端实体的主键,作为外键。
4. “多对多”关系转化为一张表,包含相关实体的主键,复合组成其自身的主键。同时这些键在SQL中定义为外键分别指向各自的实体。
5. 三元或n元关系被转化为一张表,包含相关实体的主键。这些键在SQL中定义为外键。这些键中的子集定义为主键,其基于该关系的函数依赖。
6. 泛化层次的转化规则要求子类实体从超类实体继承主键。
7. ER图中的可选约束在转化为SQL时,表现为关系的某一端实体允许为null。在ER图中没有明确标识可选约束时,创建表时默认not null约束。
下一篇:数据库设计Step by Step (10)——范式化












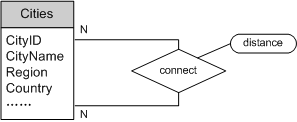





 (图1 “一对一”,两实体都为强制存在)
(图1 “一对一”,两实体都为强制存在)

 (图3 “一对一”,两实体都为可选存在)
(图3 “一对一”,两实体都为可选存在)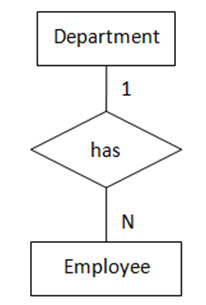
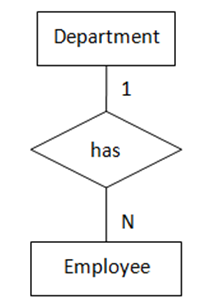 (图4 “一对多”,两实体都为强制存在)
(图4 “一对多”,两实体都为强制存在) (图5 “一对多”,一实体可选存在,另一实体强制存在)
(图5 “一对多”,一实体可选存在,另一实体强制存在)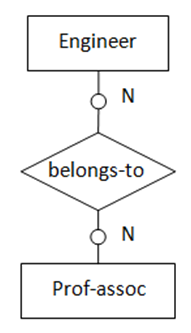
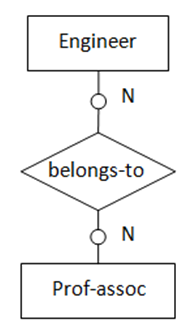 (图6 “多对多”,两实体都为可选存在)
(图6 “多对多”,两实体都为可选存在)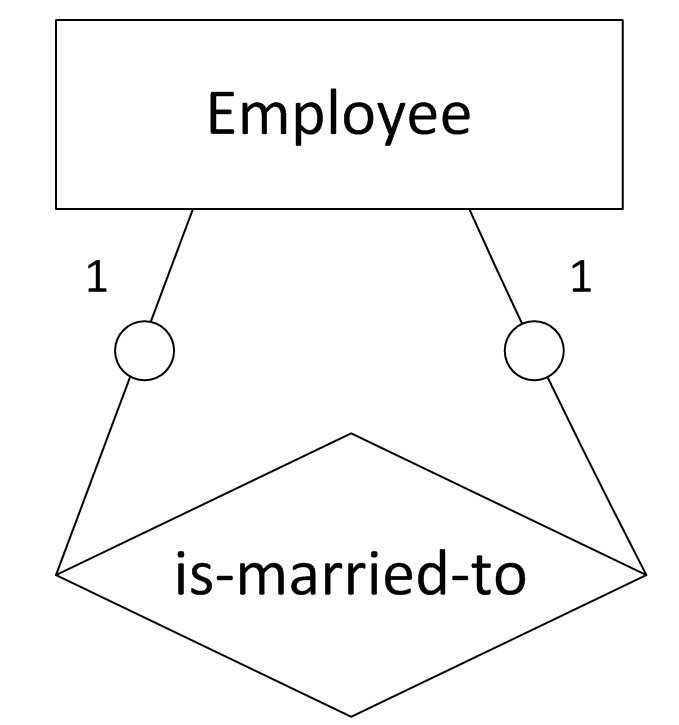

















{kind=link}