阅读原文 转自博客园 知行思新
引言:前文(数据库设计Step by Step (10)——范式化)我们详细讨论了关系数据库范式,始于第一范式止于BCNF范式。至此我们完成了数据库的逻辑设计,如下图所示。

正如首篇博文数据库设计 Step by Step (1)——扬帆启航中介绍的,本系列博文关注通用于所有关系数据库的需求分析与逻辑设计部分。无论你使用的是Oracle,SQL Server,Sybase等商业数据库,亦或是如MySQL,SQLite等开源数据库都能运用这些设计方法来优化设计。数据库的物理设计及实现部分与数据库产品密切相关、各有差异,且内容也非常丰富,故不在本系列中讨论。
本篇博文将分为两个部分,第一部分将介绍数据库设计的一些通用模式,第二部分将对本系列的内容做一个整理并给出一些参考资料供大家参考。

这一小节我们将分析一些较为常见的业务场景,并给出对于这些场景的表结构设计方法。这些方法可以放入我们自己的数据库设计工具箱,当在面对现实需求时可灵活加以运用。
多值属性
多值属性很常见,如淘宝网中每个用户都可以设置多个送货地址,又如在CRM系统中客户可以有多个电话号,一个号码用于工作时间,另一个用于下班时间等。
以存储客户的联系电话为例。联系电话是客户的属性,所以首先可能想到的一种设计方案如下:

图1这一设计满足了当前的需求,但不久我们发现客户的联系电话比我们想象的多,他们还有移动电话,而且有些客户有不止一个办公电话号码,我们需要记录这些电话号码,并标识不同的办公室地点。
对于这种需求,我们可以在Customer表中增加列,但这样做会有两方面的问题:首先,每次增加新列都需要修改数据表结构,需要DBA从后台写脚本完成,且前台显示联系电话的功能模块也需要相应进行修改。其次,每个客户具有的联系电话类型及数量各不相同,大量的联系电话单元格都是空的,浪费了许多存储空间。
我们换一种设计方案。每个客户有多个不同类型的联系电话,可以把联系电话作为弱实体从原先Customer实体中分离出来,如图2所示:

Customer与Phones之间为“一对多”关系,即一个客户可以有多个不同类型的联系电话。当我们需要给某客户增加联系电话时,我们不再需要修改表结构,只需要在Phones表中增加记录就可以了。这完全可以作为前台的功能让业务操作人员来完成,而且现在的Customer不再会存在大量空单元格了。在关系数据库中增加行比增加列的代价要小很多。
实体Phones的主键是什么?
CustID肯定是主键的一部分。主键包含的其他列根据我们想表达的不同语义,可以有所不同。
语义1:一个客户不能有重复的联系类型。即一个客户的每个PhoneType不能重复,但多个不同的PhoneType可能对应相同的PhoneNum(如:PhoneType为“Office”和“Home”对应同一个号码)。符合该语义的主键为:CustID,PhoneType;
语义2:一个客户不能有重复的联系电话。即一个客户的每个PhoneNum不能重复,但多个不同的PhoneNum可能对应相同的PhoneType(如:PhoneType为“Office”有多个不同号码)。符合该语义的主键为:CustID,PhoneNum;
语义3:一个客户的一个联系类型能有多个不同的联系电话,一个联系电话可能对应不同的联系类型。符合该语义的主键为:CustID,PhoneType,PhoneNum;
举一反三,该多值属性设计方法同样适用于维护客户的多个地址或Email等场景。
历史追溯
说到历史就会涉及时间。例如:当前物价持续上涨,同一产品的售价每个月都有可能调整,若要追溯产品价格变化的情况,仅仅记录该产品当前的一个售价是不足够的。同样对于银行中的利率变化,购入原材料的单价变化等,都需要进行历史追溯。
要跟踪一个实体随时间的变化可以在该实体中增加属性列,指明实体中每个实例的有效日期。图3展示了可追溯产品价格的订单结构(已经过简化)。

实体Orders记录订单的公共信息,包括订单号(OrderID),下订单的时间(OrderDate),客户编号(CustomerID)等。其中OrderID提供了到实体OrderItems的联接。实体OrderItems记录客户订购的产品条目,包括所属订单号(OrderID),产品编号(ProductID),订购数量(Quantity)等。其中ProductID能联接到实体Products。实体Products中包含每种产品的描述信息。实体ProductPrices记录了产品的价格,包括产品编号(ProductID)对应到Products实体,产品价格(Price),以及该价格的有效时间段(EffectiveStartDate,EffectiveEndDate)。
对于上述表结构,回溯历史某个订单的信息的步骤如下:
1. 根据订单号(OrderID)在Orders表中找到对应的记录,并记录下OrderDate
2. 在OrderItems表中根据OrderID找到对应的所有订单明细记录。对每一条明细,记录下Quantity和ProductID,之后:
a. 通过ProductID,在Products表中找到对应产品的产品描述(Description)
b. 在ProductPrices表中找到对应ProductID,且EffectiveStartDate <= OrderDate < EffectiveEndDate的记录。该记录中的Price为指定产品在历史下单时的价格。
这样我们就得到了该订单的历史“快照”信息。
需要注意的几点:
1. 如果我们只需要追溯订单中产品的历史价格,可省去上述步骤中的a。
2. 上述订单表结构在每次查看订单时都需要查询ProductPrices表。我们可以通过在OrderItems表中增加ItemPrice列,来避免对ProductPrices表的频繁查询。当创建订单明细记录时,把从ProductPrices中查询到的价格记录到ItemPrice列中,之后每次查看订单时就不需要再查询ProductPrices表了。
3. ProductPrices表的主键为ProductID,EffectiveStartDate。同时该表还隐含着约束:同一种产品的价格有效时间段不能重叠。
4. ProductPrices表结构中EffectiveEndDate列可省去,把该产品的下一个EffectiveStartDate作为上一个有效时间段的自然结束时间点。但这样做会增加查询的复杂度。
在举一个简单的例子,每个客户只有一个地址信息,但希望能跟踪客户地址的变更情况。我们能设计如下(图4)表结构:

类似的场景包括:跟踪员工薪资的变化情况,跟踪汇率的变化情况等等。还有一种场景可使用该技术,当我们通过系统前台试图删除某信息时,系统的后台数据库并不真正去做删除操作,而是通过EffectiveEndDate标识记录的无效时间。通过EffectiveStartDate和EffectiveEndDate可回溯任何历史时间点存在的记录“快照”。
树型结构
树型结构最典型的例子是员工组织机构图,如图5所示。
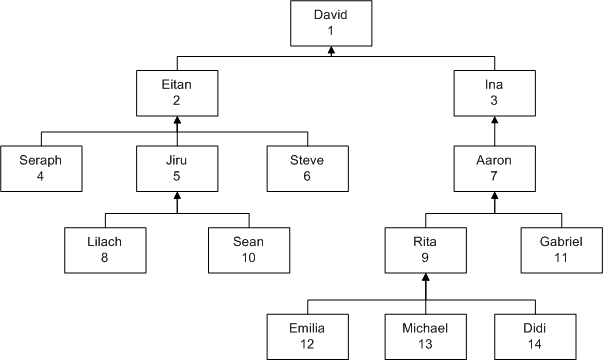
树型结构中除根节点之外,每一个子节点都有一个父节点。可以把节点建模为一个实体,父子之间的联系建模为“一对多回归关系”。图5中的员工组织结构可建模为图6所示的ER结构。
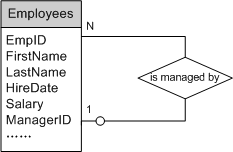
实体Employees中的EmpID,FirstName,LastName,HireDate,Salary等属性描述了员工的基本信息,树型层次关系通过ManagerID属性进行描述,该属性存储了该员工的经理ID,即指向其父节点。
在节点实体中存储指向父节点的属性已足够描述树型结构的语义,但为了提高查询的效率,设计中可增加树型结构层次(Lvl)和物化路径(Path)作为辅助信息。图5员工组织结构样例数据如下:
| EmpID | FirstName | LastName HireDate … | ManagerID | Lvl | Path |
| 1 | David | …… | NULL | 0 | .1. |
| 2 | Eitan | …… | 1 | 1 | .1.2. |
| 4 | Seraph | …… | 2 | 2 | .1.2.4. |
| 5 | Jiru | …… | 2 | 2 | .1.2.5. |
| 10 | Sean | …… | 5 | 3 | .1.2.5.10. |
| 8 | Lilach | …… | 5 | 3 | .1.2.5.8. |
| 6 | Steve | …… | 2 | 2 | .1.2.6. |
| 3 | Ina | …… | 1 | 1 | .1.3. |
| 7 | Aaron | …… | 3 | 2 | .1.3.7. |
| 11 | Gabriel | …… | 7 | 3 | .1.3.7.11. |
| 9 | Rita | …… | 7 | 3 | .1.3.7.9. |
| 12 | Emilia | …… | 9 | 4 | .1.3.7.9.12. |
| 13 | Michael | …… | 9 | 4 | .1.3.7.9.13. |
| 14 | Didi | …… | 9 | 4 | .1.3.7.9.14. |
(表1 员工组织结构数据,其中Lvl列,Path列可选,利用该两列能提升某些查询的性能)
注:如何对树型结构数据表进行查询、遍历在这里不进行展开,可参考《Inside Microsoft SQL Server 2005 T-SQL Querying》一书。本例及以下两小节中的例子,引用自《Inside Microsoft SQL Server 2005 T-SQL Querying》,但同样适用于其他关系数据库。
有向无环图结构
有向无环图(DAG)的典型应用场景是物料清单(BOM)。BOM记录了产品的组装零件或配置方式,下图为某咖啡店的BOM图,描述了配置每种饮料的原料及剂量。
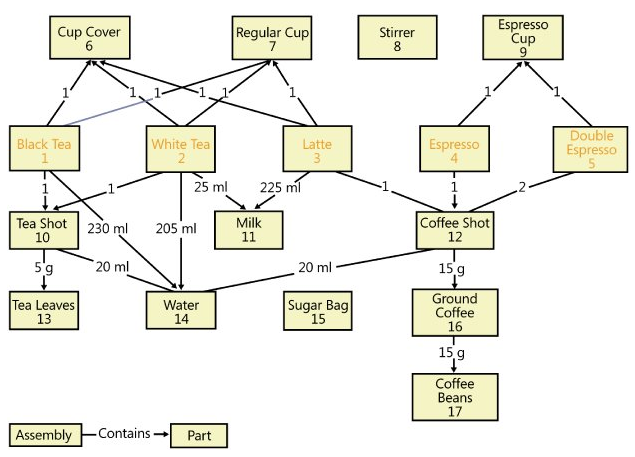
我们如何把这一BOM信息存储到数据库中呢?
BOM场景以有向无环图为模型。有向无环图与树型层次结构的差异之处在于,有向无环图中的一个节点能有多个父节点。故ER模型中,有向无环图需建模成两个实体,一个实体用于描述节点,另一个实体用于描述节点之间的边。咖啡店BOM场景的ER模型如图7所示,实体Parts表示咖啡店的原料及饮品,实体Assemble表示原料配置的方向(即“有向边”),其中还包括边的权值,此例中边的权值为qty,表示配料的剂量,unit为配料的剂量单位(如:g,ml等)。
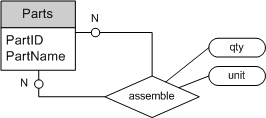
把咖啡店BOM的ER图转化为SQL:
create table Parts
(
PartID int not null primary key,
PartName varchar(25) not null
);
create table Assemble
(
PartID int not null references Parts,
AssemblyID int not null references Parts,
Unit varchar(3) not null,
Qty decimal(8,2) not null,
primary key(PartID, AssemblyID),
check(PartID <> AssemblyID)
);需要注意以下几点:
1. 上述代码在SQL Server 2008下测试通过。对于其他数据库产品,代码细节可能需稍作调整,但主体设计结构不变。
2. Assemble表的主键为:PartID,AssemblyID。
3. Assemble表的PartID列和AssemblyID列外键引用Parts表。
4. Assemble表的check约束保证其中任何记录的PartID与AssemblyID的值不会相同。
无向循环图结构
无向循环图的一个典型例子是城市道路系统。下图展示了美国主要城市之间的道路
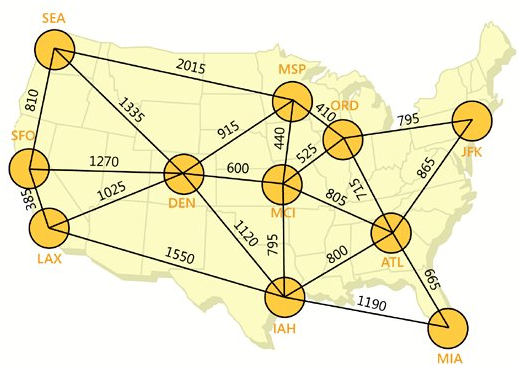
图8中每个节点表示一个城市,城市之间的连线代表城市之间的道路,连线上的数值表示距离。道路系统以无向循环图为模型,无向循环图中的节点能与任意数量的其他节点相连,且相连接的节点之间没有父子或先后关系(即“边”没有方向)。对图8中的道路系统进行ER建模得:
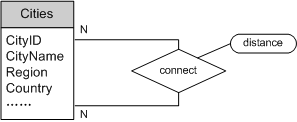
把图9中的ER模型转化为SQL:
create table Cities
(
CityID char(3) not null primary key,
CityName varchar(30) not null,
Region varchar(30) not null,
Country varchar(30) not null
);
create table Roads
(
CityID char(3) not null references Cities,
DestID char(3) not null references Cities,
Distance int not null,
primary key(CityID, DestID),
check(CityID < DestID),
check(Distance > 0)
);需要注意以下几点:
1. 上述代码在SQL Server 2008下测试通过。对于其他数据库产品,代码细节可能需稍作调整,但主体设计结构不变。
2. 为了更易于理解,图9道路系统ER模型中的关系connect,在转化为SQL表时更名为Roads。Roads表描述了一个无向循环赋权图。表中每一行表示一条边(道路)。Distance属性表示权值(城市间的距离)。
3. Roads表的CityID列和DestID列外键引用CityID表。
4. Roads表的主键为CityID,DestID。
5. Roads表中包含check约束(CityID < DestID),以避免存入两个相同的边(eg:“芝加哥到纽约”和“纽约到芝加哥”)。无向循环图中节点之间是平等的,故该约束很重要,避免冗余数据。
6. 若要扩展到“有向循环图”场景(如:道路系统中的单行道),我们只要去除check约束(CityID < DestID),此时不同方向的数据不再是冗余。

到这里整个系列将告一段落,希望大家能觉得该系列言之有物,读了能有些许收获。最后,对本系列博文作一个回顾,同时给出一些参考资料。
本系列篇目回顾
1. 数据库设计 Step by Step (1)——扬帆启航
2. 数据库设计 Step by Step (2)——数据库生命周期
3. 数据库设计 Step by Step (3)——基本ER模型构件
4. 数据库设计 Step by Step (4)——高级ER模型构件
5. 数据库设计 Step by Step (5)——理解用户需求
6. 数据库设计 Step by Step (6) —— 提取业务规则
7. 数据库设计Step by Step (7)——概念数据建模
8. 数据库设计 Step by Step (8)——视图集成
9. 数据库设计Step by Step (9)——ER-to-SQL转化
10. 数据库设计Step by Step (10)——范式化
11. 数据库设计Step by Step (11)——通用设计模式(系列完结篇)
参考资料
以下推荐的两本书虽然不是关于数据库设计,但对于程序开发人员会有帮助。熟练掌握数据库查询与编程能促进对数据库设计的理解与学习。
1. 《Inside Microsoft SQL Server 2005 T-SQL Querying》——这是我当初看的一本书,对于深入理解数据库查询很有帮助。现在已经出了《Inside Microsoft SQL Server 2008 T-SQL Querying》。
2. 《Inside Microsoft SQL Server 2005 T-SQL Programming》——对于学习T-SQL编程很有助益。