参考
字符编码基础知识其一
字符编码笔记:ASCII,Unicode 和 UTF-8 ——阮一峰
分享一下我所了解的字符编码知识
字符编码详解及由来(UNICODE,UTF-8,GBK)
字符编码详解(基础) ——PHP鸟哥
文件和字符编码
编码方式之ASCII、ANSI、Unicode概述
字节 (Byte或byte):计算机系统中用于计量存储容量的一种计量单位, 1B=8bit
字符 (Character)是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等,但是一个字符在计算机中占用多少字节是与编码方式有关的,不同的编码方式占用的内存不一样。例如:标点符号+是一个字符,汉字我们是两个字符,在GBK编码中一个汉字占2个字节,在UTF-8编码中一个汉字占3个字节。
mysql(utf8mb4编码)中varchar(255) 255是字符长度不需要考虑不同字符(中文,英文)字节占用问题这是mysql底层处理的
字节 和字符 有什么联系和区别呢?简单来说字节是计算机存储和操作的最小单位,字符是人们阅读的最小单位 ;字节是存储(物理)概念 ,字符是逻辑概念 ;字节代表数据 (内涵和本质),字符代表其含义 ;字符由字节组成 。int32类型表示只需4个字节编码规范 随着计算机的普及,人们希望能在计算机中显示字符,但是计算机只能显示0和1这样的二进制数,为了显示字符,国际组织就制定了编码规范,希望使用不同的二进制数来表示代表不同的字符,这样电脑就可以根据二进制数来显示其对应的字符。所谓字符集其实就是一套编码规范中的子概念,所以我们通常就称呼其为XX编码,XX字符集。例如:GBK 编码规范,根据这套编码规范,计算机就可以在中文字符和二进制数之间相互转换。而使用GBK编码就可以使计算机显示中文字符。
字库表 一套编码规范不一定包含世界上所有的字符,每套编码规范都有自己的使用场景,而字库表就存储了某种编码规范中能显示的所有字符,计算机就是根据二进制数 从字库表中找到与之对应的字符然后显示给用户的 ,字库表相当于一个存储字符的数据库 。例如:几乎所有汉字都保存在GBK 编码规范的字库表 中。所以可以显示汉字,但法语,俄语并不在其字库表中,所以使用GBK编码的文档不能正常显示法语,俄语等不包含在其字库表中的字符。
编码字符集(字符集) 在一个字库表中,每一个字符都有一个对应的二进制地址,而编码字符集就是这些地址的集合。字符集定义了字符和二进制的对应关系 ,为每个字符分配了唯一的编号。可以将字符集理解成一个很大的表格,它列出了所有字符和二进制的对应关系,计算机显示文字或者存储文字,就是一个查表的过程 。
字符编码(编码方式 ) 而字符编码规定了如何将字符的编号存储到计算机中,如果使用了类似 GB2312 和 GBK 的变长存储方案(不同的字符占用的字节数不一样),那么为了区分一个字符到底使用了几个字节,就不能将字符的编号直接存储到计算机中,字符编号在存储之前必须要经过转换,在读取时还要再逆向转换一次,这套转换方案就叫做字符编码。
字符集和字符编码的关系
通常特定的字符集采用特定的编码方式(即一种字符集对应一种字符编码(例如:ASCII、IOS-8859-1、GB2312、GBK,都是即表示了字符集又表示了对应的字符编码,但Unicode不是,它采用现代的模型) ),因此基本上可以将两者视为同义词https://www.cnblogs.com/lanhaicode/p/11214827.html
粗略总结
解码过程:一个较短的二进制数,通过一种编码方式,转换成编码字符集中正常的地址,然后在字库表中找到一个对应的字符,最终显示给用户。 编码过程:字库表中的一个文字或符号,在字符集中找到对应的二进制串,然后通过一种编码方式,存储到计算机存储设备中 常见的编码规范及其发展过程
单字节
ASCII (American Standard Code for Information Interchange,美国信息交换标准代码),是最早产生的编码规范,共128个字符,用7位二进制表示(00000000-01111111即0x00-0x7F),可以看出ASCII码只需要1个字节的存储空间,它没有特定的编码方式,直接使用地址对应的二进制数来表示,非要说那就叫他ASCII 编码方式。可以表示阿拉伯数字和大小写英文字母,以及一些简单的符号。
EASCII (Extended ASCII),256个字符,用8位二进制表示(00000000-11111111即0x00-0xFF)。当计算机传到了欧洲,国际标准化组织在ASCII的基础上进行了扩展,形成了ISO-8859标准,跟EASCII类似,兼容ASCII,在高128个码位上有所区别。ISO-8859-1编码范围使用了单字节内的所有空间,在支持ISO-8859-1的系统中传输和存储其他任何编码的字节流都不会被抛弃。换言之,把其他任何编码的字节流当作ISO-8859-1编码看待都没有问题。这是个很重要的特性
MySQL数据库默认编码是Latin1就是利用了这个特性。ASCII编码是一个7位的容器,ISO-8859-1编码是一个8位的容器。由此可见,ISO-8859-1只占1个字节,且MySQL数据库默认编码就是ISO-8859-1,有时,tomcat服务器默认也是使用ISO-8859-1编码,然而ISO-8859-1是不支持中文的,有时这就是在浏览器上显示乱码的原因。但是由于欧洲的语言环境十分复杂,所以根据各地区的语言又形成了很多子标准,ISO-8859-1、ISO-8859-2、ISO-8859-3、……、ISO-8859-16。
双字节
当计算机传到了亚洲,256个码位就不够用了。于是乎继续扩大二维表,单字节改双字节,16位二进制数,65536个码位。在不同国家和地区又出现了很多编码,中国的GB2312 、港台的BIG5 、日本的Shift JIS ,韩国的Euc-kr 等等。
GBK 全称《汉字内码扩展规范》,支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字。GBK字符集中所有字符占2个字节,不论中文英文都是2个字节。 没有特殊的编码方式,习惯称呼GBK 编码。
一般在国内,汉字较多时使用。GBK(Chinese Internal Code Specification)是GB2312的扩展,GBK 向下与 GB 2312 编码兼容,向上支持 ISO 10646.1国际标准,是前者向后者过渡过程中的一个承上启下的产物。ISO 10646 是国际化标准组织 ISO 公布的一个编码标准,即 Universal Multilpe-Octet Coded Character Set(简称UCS),与 Unicode 组织的 Unicode 编码完全兼容。 多字节
当互联网席卷了全球,地域限制被打破了,不同国家和地区的计算机在交换数据的过程中,由于之前出现的各种不同的编码方式,文本就会出现乱码的问题,即对同一组二进制数据,不同的编码会解析出不同的字符。而当某个字符集中没有文本中的字符编码时,就会出现乱码。
通用字符集UCS(Universal Character Set) 对应两种编码:对每一个字符采用四个8比特字节编码的称为UCS-4,对每一个字符采用两个8比特字节编码的称为UCS-2。
Unicode字符集 的出现就是为了解决这个问题。Unicode 是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严。具体的符号对应表,可以查询unicode.org ,或者专门的汉字对应表 。
需要注意的是,Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字严的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是,如何才能区别 Unicode 和 ASCII ?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:1)出现了 Unicode 的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示 Unicode。2)Unicode 在很长一段时间内无法推广
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8 是 Unicode 的实现方式之一。
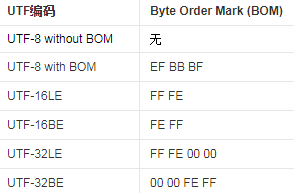
BOM
BOM(字节顺序标记, byte-order mark)也是我们常见到的名词, 比如我们的代码文件都要求使用UTF-8无BOM形式保存, 不然有可能编译不过, 或者出现一些诡异的事情.UTF-16 LE
对于UTF-8, 由于它使用的是8位的码元, 不存在字节序的问题, 也不建议在头部添加BOM, 因为可能影响到一些工具, 因此使用无BOM的UTF-8成了主流.
ANSI
ANSI全称(American National Standard Institite)美国国家标准学会(美国的一个非营利组织),首先ANSI不是指的一种特定的编码,而是不同地区扩展编码方式的统称,各个国家和地区所独立制定的兼容ASCII,但互相不兼容的字符编码,微软统称为ANSI编码
总结对照
常用的字符编码ASCII,GBK,GB2312,BIG5,UTF-8 英文和中文简繁
Unicode字符集的编码方式有UTF-8,UTF-16,UTF-32
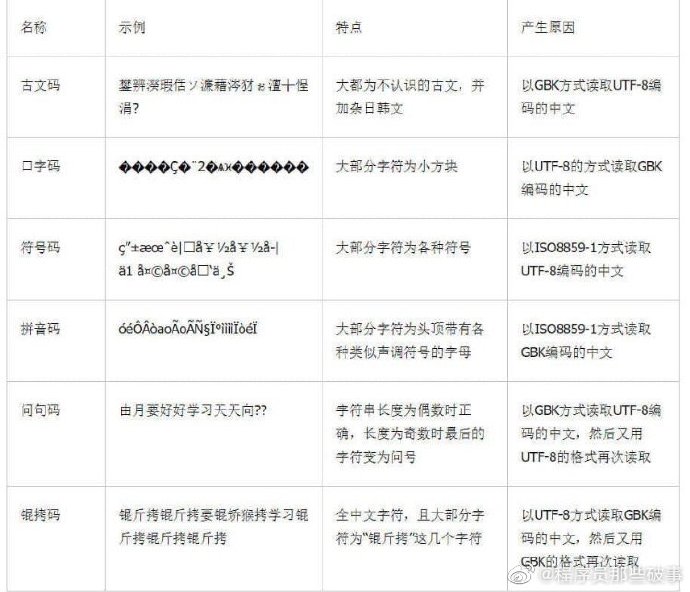
中文乱码产生的原因
PHP获取中文的第一个字符
//多字节字符串 PHP文件编码为UTF-8
$str = '你好PHP';
var_dump($str[0]); //输出结果 b"ä",乱码
var_dump(substr($str, 0, 1));//输出结果 b"ä",乱码
var_dump(substr($str, 0, 3));//输出结果 你 ,utf-8编码中一个汉字是三个字节
var_dump(mb_substr($str, 0, 1));//输出结果 你PHP处理字符串的方式默认是把字符串作为单字节字符处理的,例如数组方式取字符和普通字符串函数
PHP处理多字节字符串需要用这些扩展 国际化与字符编码支持 常用的有mbstring 扩展和 iconv 函数
mbstring扩展支持的编码 https://www.php.net/manual/zh/mbstring.supported-encodings.php
iconv_get_encoding 获取 iconv 扩展的内部配置变量,
文本文件和二进制的区别
文本文件是二进制文件的一种,底层存储也是0和1;文本文件可读性和移植性好,但表现字符有限;二进制文件数据存储紧凑,无字符编码限制。文本文件基本上只能存放数字、文字、标点等有限字符 组成的内容;二进制没有字符约束,可随意存储图像、音视频等数据。
用存储数字的例子可以形象的看出文本文件和二进制文件存储内容上的差异。例如要存储数字1234567890,文本文件要存储0-9这十个数字的ASCII码,对应的十六进制表示为:31 32 33 34 35 36 37 38 39 30,占用10个字节;1234567890对应的二进制为“0100 1001 1001 0110 0000 0010 1101 0010”,占用4个字节(二进制表示32位,一个字节8位),存储到文件的16进制表示为(大端):49 96 02 D2。
文本文件按字符 存放内容,二进制按字节 存放,这是两种文件最本质的区别。根据这个特性,可以推断出一些常见结论:二进制文件常常比文本文件紧凑,占用空间少;文本文件更友好易用,能用所见即所得的方式编辑;二进制文件常常需要专用程序打开,等等。
回过头看文本编辑器打开二进制文件常常是乱码的现象。例如一个二进制文件存放了一个整数1234(四个字节),用16进制表示为:00 00 04 D2。文本编辑器打开后逐个字符解释,会发现这几个字节拼不出可显示的字符,只好乱码相待。乱码的原因是文本编辑器不能正确解析字节流,这也是二进制文件需要用专用软件打开的原因。例如jpg文件要用看图软件打开,如果用音乐播放器打开,完蛋!视频文件要用播放器打开,用压缩软件打开,歇菜!有的专用软件会做处理打开不支持的格式后不做反应,有的会报错。
文件格式
Windows按文件拓展名识别文件格式,并调用对应的程序打开文件;
(类)Unix系统,拓展名可有可无,有file命令,这个命令可以告诉我们文件到底是什么格式文件拓展名不是文件格式的本质区别,内容才是。把a.zip改成a.txt/a.jgp/a.mp3,无论什么文件名,file都让其原形毕露:Zip archive data, at least v1.0 to extract。file命令的工作原理可这篇文章 。
PHP读取txt文本文件获取第一个字符乱码
参考
PHP检测文件BOM头
ANSCII编码对照表
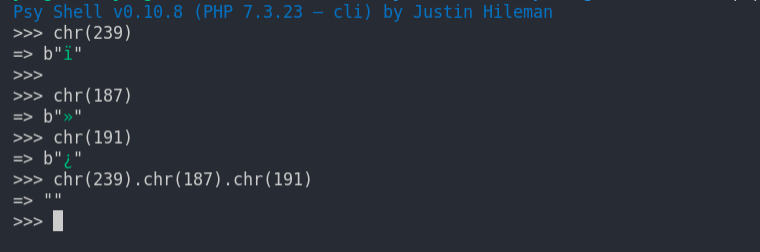
有一个ASCII的编码的文本文件,在linux上打开会显示乱码,因此使用windows记事本打开转成了UTF-8编码,然后用php读取该文本文件第一个字符时出现乱码,原因是windows记事本保存文件时会给文本文件增加bom头。
php检测处理bom头的原理 ,就是用ord函数检测前三个字符在ASCII编码中的数字是否为239,187,191
if (ord($contents[0]) === 239 && ord($contents[1]) === 187 && ord($contents[2]) == 191)
{
$contents = substr($contents, 3);
var_dump($contents[0]);
}对应的字符如下
用户的操作系统类型是不确定,因此文本文件的字符编码也无法确定 ,需要对用户上传的文本文件转换字符编码
$fileContents = file_get_contents($path);//读取文件字符串,此处可以用框架方法替代
$encoding = mb_detect_encoding($fileContent, ['ASCII', 'GBK', 'GB2312', 'BIG5', 'UTF-8']);//获取文件内容编码
$fileContent = mb_convert_encoding($fileContent, 'UTF-8', $encoding);//转码
//$contents = iconv($encoding, 'UTF-8', $contents);//iconv也可以