GuzzleHttp\Exception\RequestException: cURL error 60: SSL certificate problem: unable to get local issuer certificate (see http://curl.haxx.se/libcurl/c/libcurl-errors.html)
<?php
// Fork the current process
$pid = pcntl_fork();
// If pid is negative, an error occurred
if ($pid == -1) {
exit("Error forking...\n");
}
// If pid is 0, this is the child process
elseif ($pid === 0) {
// Make the child process a new session leader
if (posix_setsid() === -1) {
exit("Error creating new session...\n");
}
$dir = '../../../vendor/mydaemon.log';
// Open a log file for writing
$log = fopen($dir, 'w');
// Loop indefinitely
while (true) {
// Write a message to the log file
fwrite($log, "Daemon is running...\n");
// Sleep for 5 seconds
sleep(5);
}
//close the standard input, output, and error streams respectively.
//REF:https://www.php.net/manual/zh/wrappers.php.php
//REF:https://www.php.net/manual/zh/features.commandline.io-streams.php
fclose(STDIN);
fclose(STDOUT);
fclose(STDERR);
}
// If pid is positive, this is the parent process
else {
// Exit the parent process
exit('Exit the parent process');
}
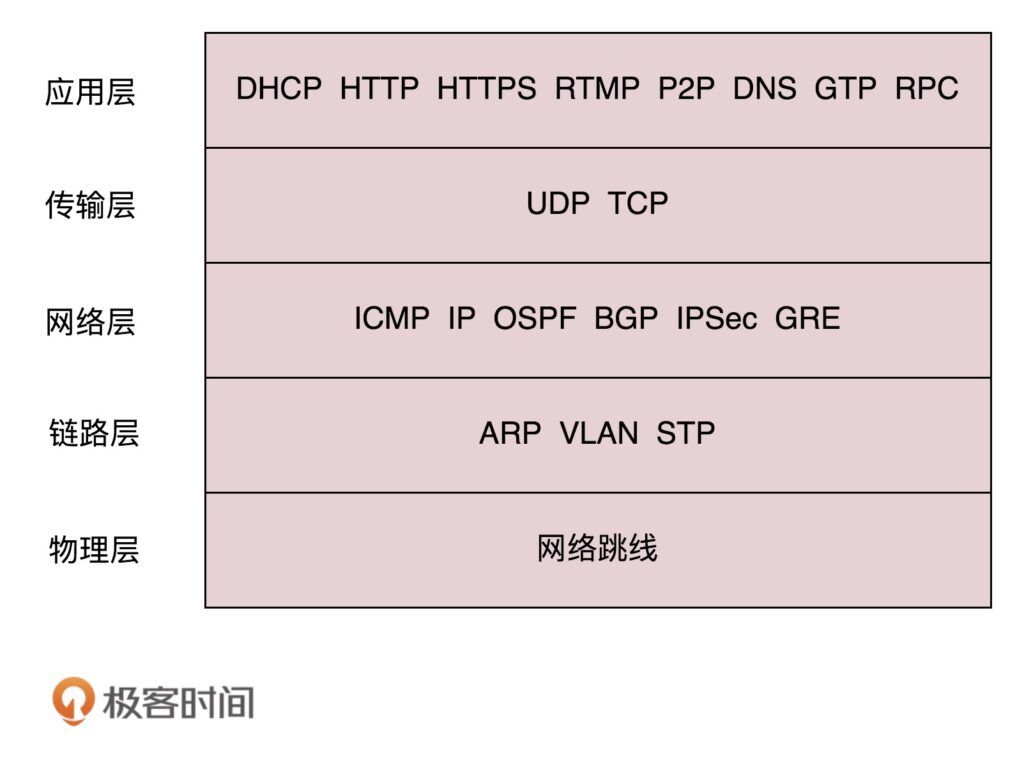
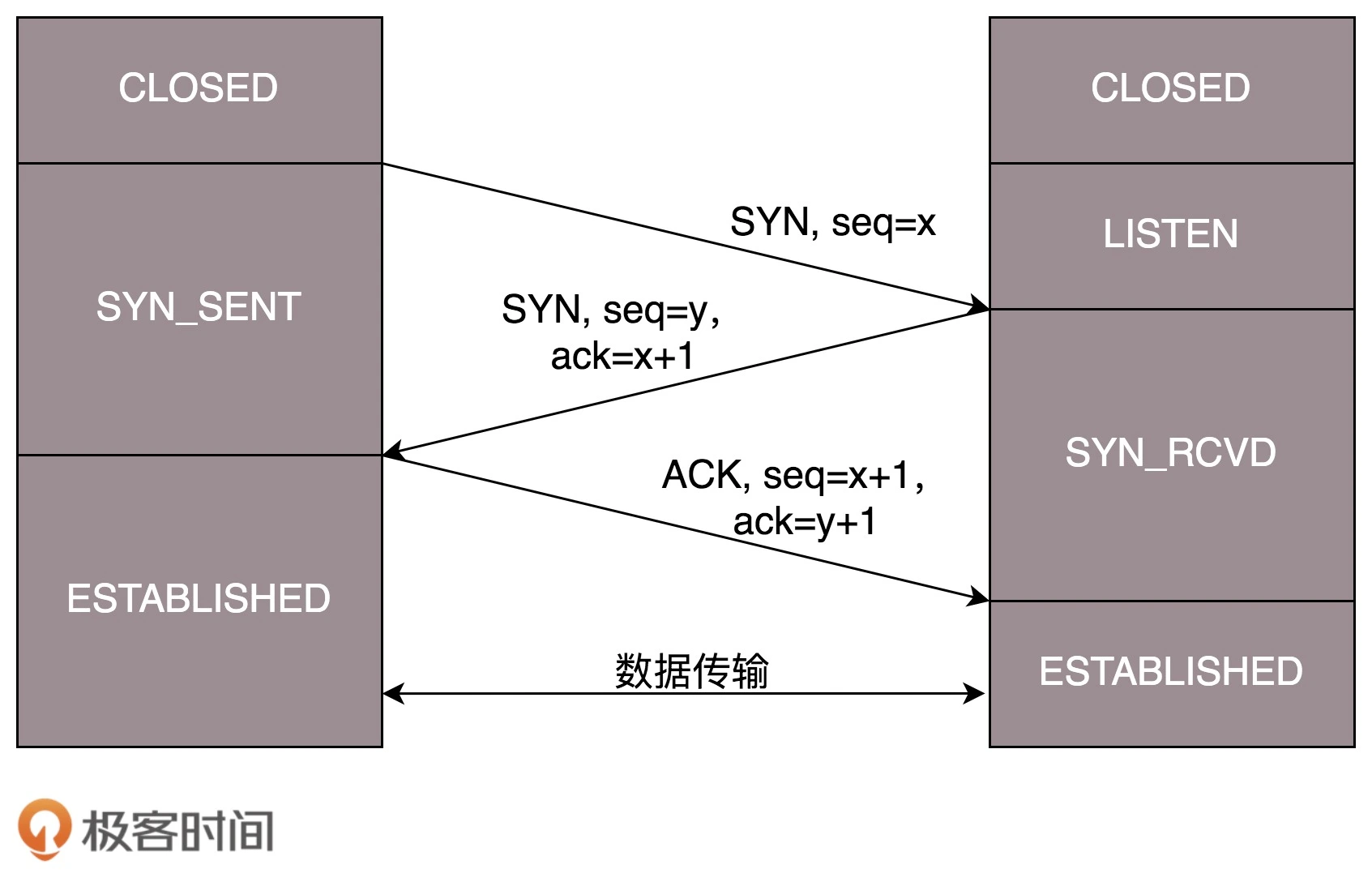
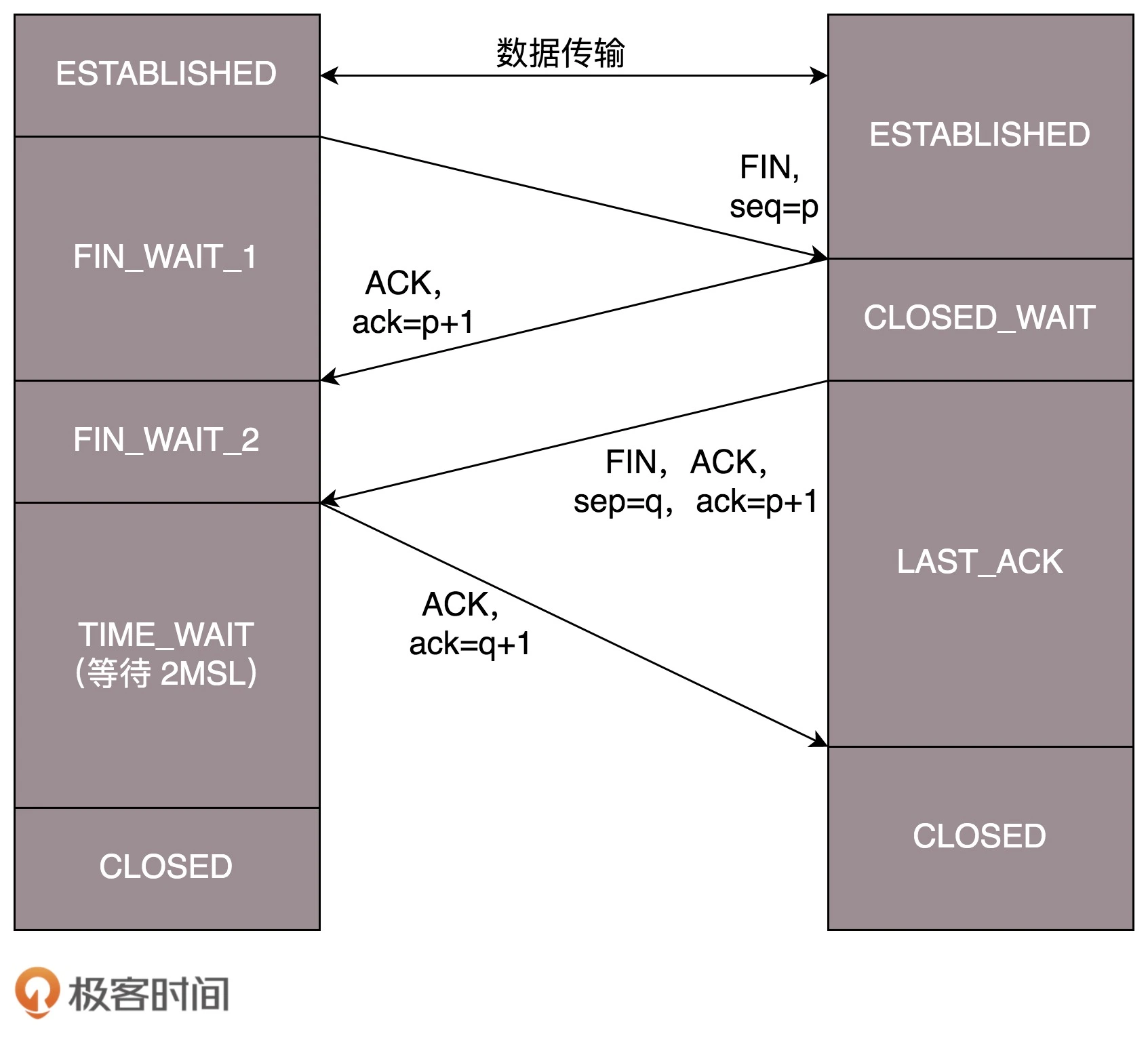
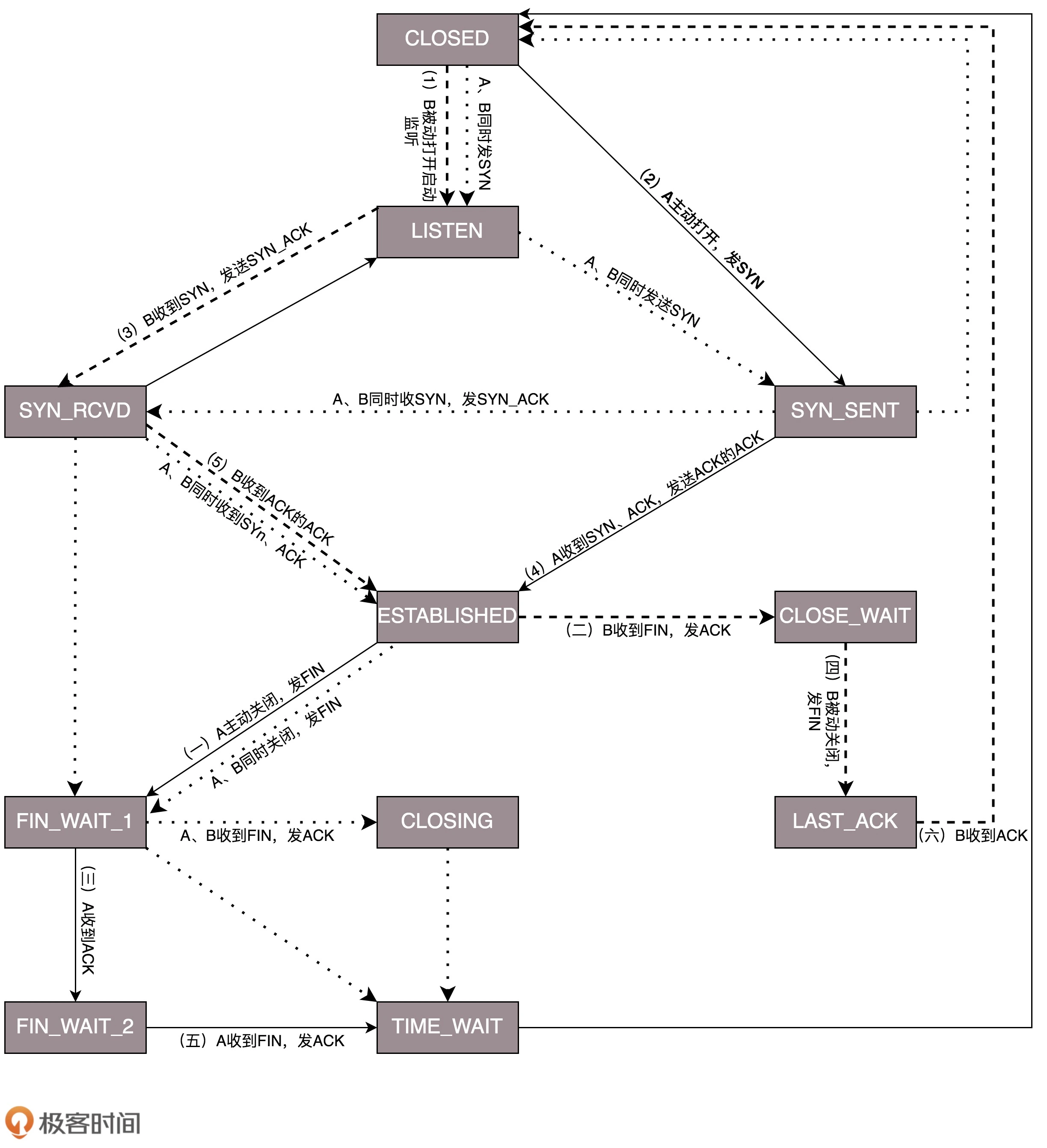
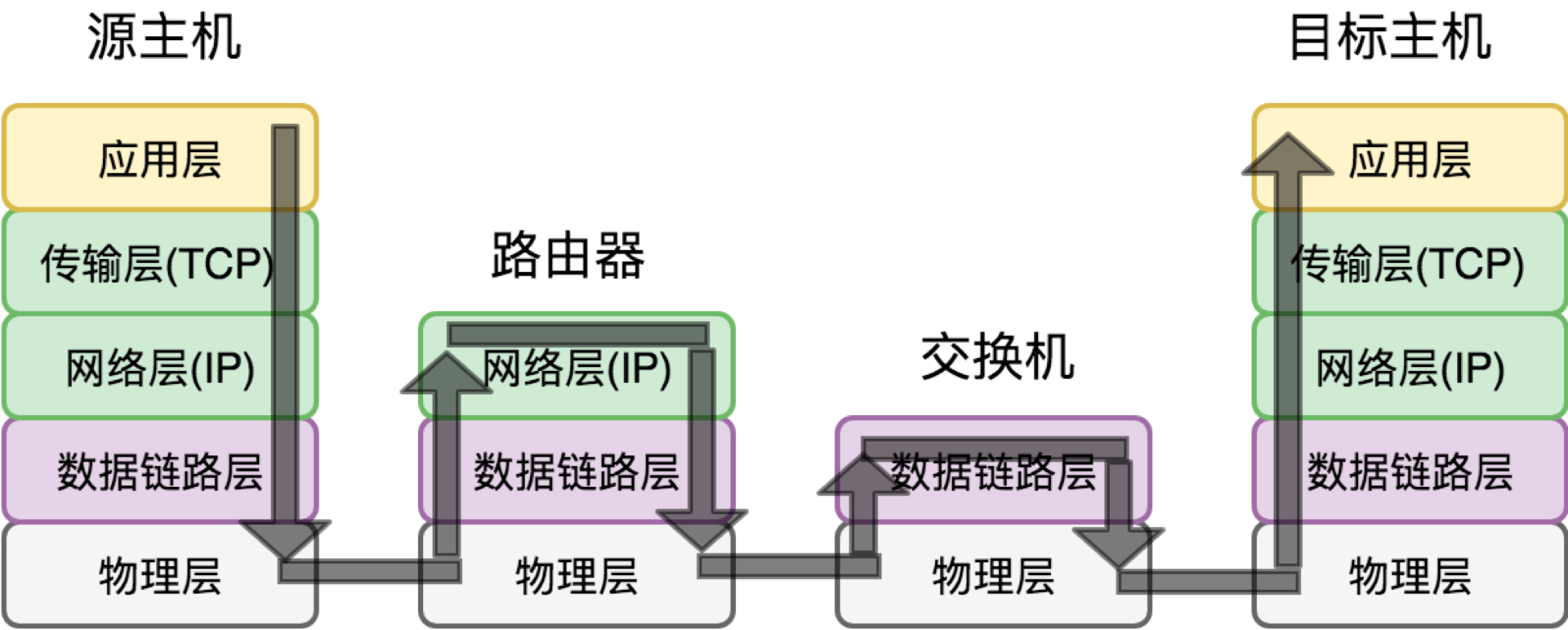
DHCP 全称叫动态主机配置协议(Dynamic Host (主机) Configuration Protocol (协议) ),主要负责计算机接入网络时的初始化。计算机刚开始就只有网卡的 MAC 地址,通过 DHCP 可以给它分配 IP 地址,并得到默认网关地址(这很重要,不知道网关就上不了网)和 DNS 服务器的地址。有了这些东西,这台计算机就可以和外界通讯了
ARP 协议
IP => Mac 根据ip地址获取mac地址
ARP 全称叫地址解析协议( Address (地址) Resolution Protocol),它服务于现在局域网中最流行的以太网协议。在以太网中,ARP 协议负责解析远程主机 IP 地址对应的 MAC 地址。之所以需要 ARP 协议,是因为我们平常应用程序连接目标计算机进行网络通讯时,都是提供了域名或 IP 地址。但对以太网来说,要想发信件出去,它要的是对方的 MAC 地址。
RARP 协议
RARP 全称叫反向地址转换协议(Reverse Address (地址) Resolution Protocol (协议) )。顾名思义,它和 ARP 协议相反,负责的是 MAC 地址到 IP 地址的转换。RARP 协议已经被上面的 DHCP 协议所取代,平常用不太到了。
ICMP 协议
ICMP 全称叫互联网控制报文协议(Internet Control Message Protocol),它能够检测网路的连线状况,以保证连线的有效性。基于这个协议实现的常见程序有两个:ping 和 traceroute,它们可以用来判断和定位网络问题。
IGMP 协议
IGMP 全称叫互联网组管理协议(Internet Group Management Protocol (协议) ),它负责 IP 组播(Multicast)成员管理