分类: MySql优化
Mysql FAQ
隐式类型转换
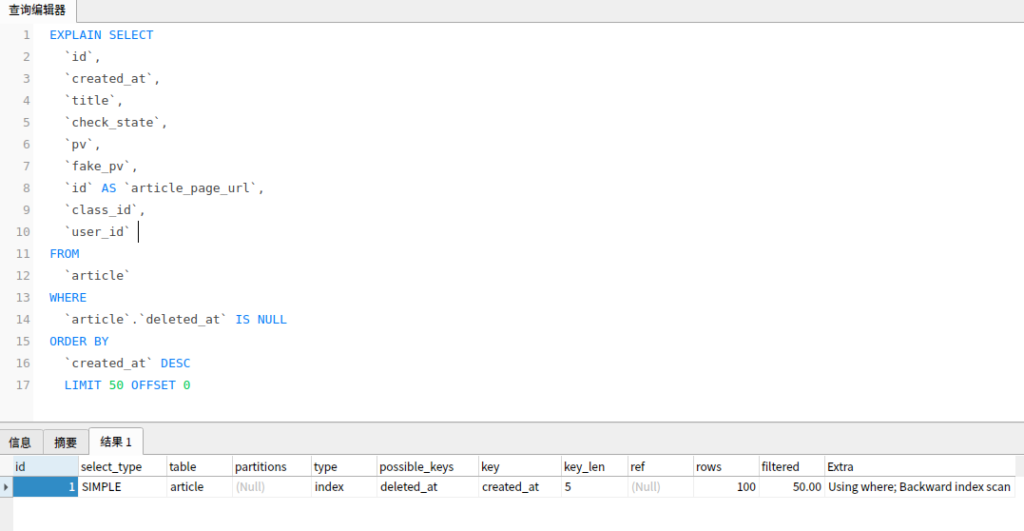
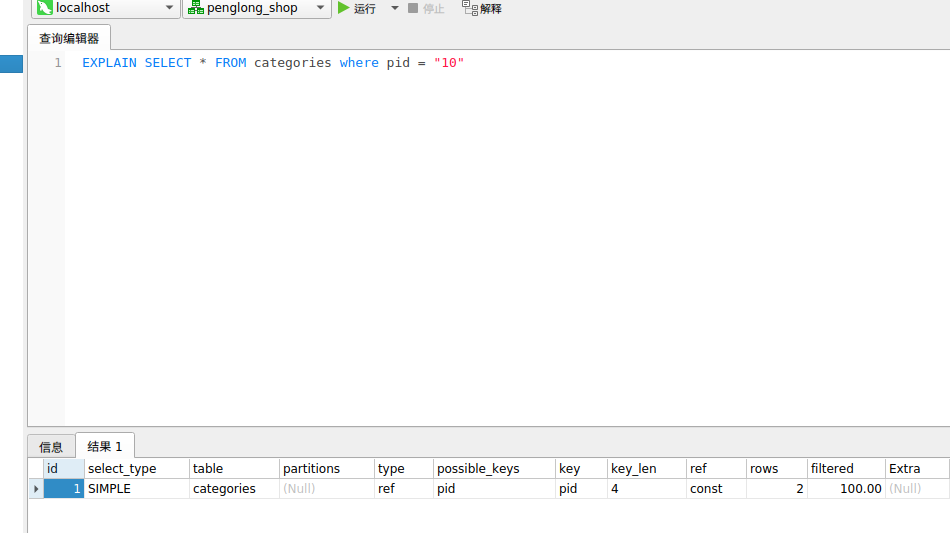
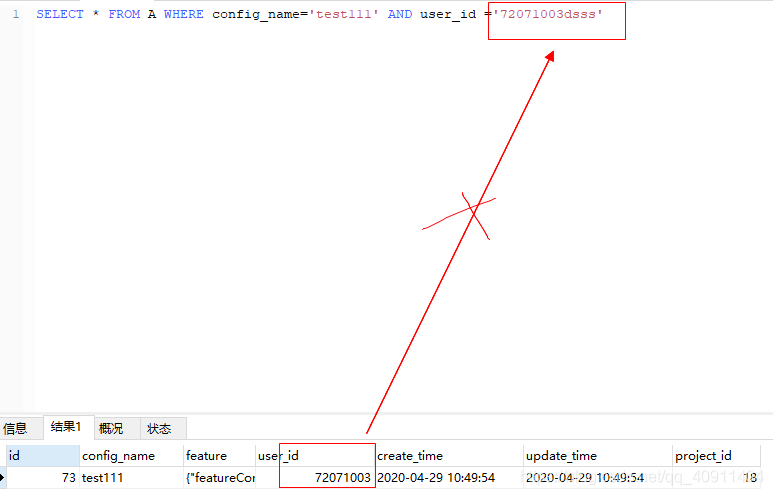
例如 pid 字段类型是 int,我们 where pid = “1”,这样就会触发隐式类型转换。字段为数字类型,字符串数字转换成数字时,并不会导致索引失效如下图
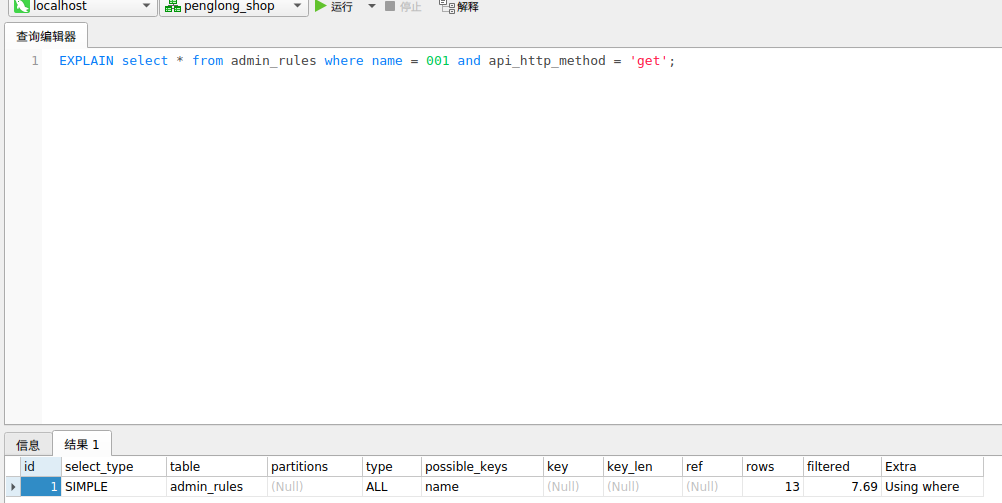
当where查询操作符**左边为字符类型**时发生了隐式转换,那么会导致索引失效,造成全表扫描效率极低。
name为字符串类型,传入了数字类型001 转换后索引失效
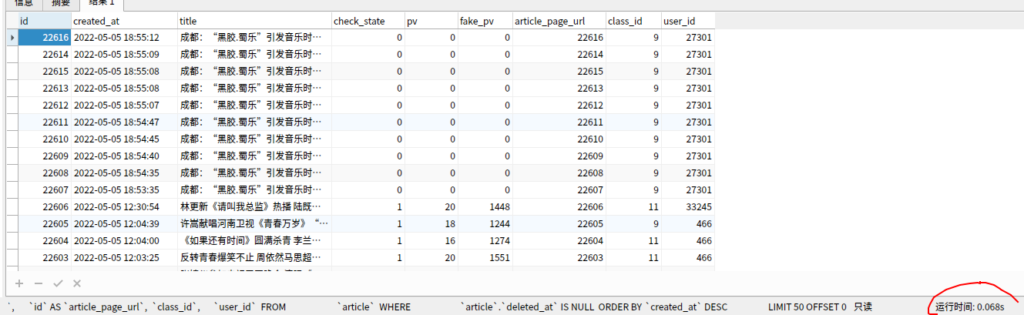
导致查询结果不符合预期
类型隐式转换规则
当操作符与不同类型的操作数一起使用时,会发生类型转换以使操作数兼容,某些转换是隐式发生的
如果不与数字比较,则将十六进制值视为二进制字符串
如果参数之一是a TIMESTAMP或 DATETIME column,而另一个参数是常量,则在执行比较之前,该常量将转换为时间戳。这样做是为了使ODBC更友好。对于的参数,此操作未完成 IN()。为了安全起见,在进行比较时请始终使用完整的日期时间,日期或时间字符串。例如,要在BETWEEN与日期或时间值一起使用时获得最佳结果 ,请使用CAST()将值显式转换为所需的数据类型。
一个或多个表中的单行子查询不被视为常量。例如,如果子查询返回要与DATETIME 值进行比较的整数,则比较将作为两个整数进行。整数不转换为时间值。要将操作数作为DATETIME值进行比较 ,请使用 CAST()将子查询值显式转换为DATETIME
如果参数之一是十进制值,则比较取决于另一个参数。如果另一个参数是十进制或整数值,则将参数作为十进制值进行比较;如果另一个参数是浮点值,则将参数作为浮点值进行比较。
在所有其他情况下,将参数作为浮点数(实数)进行比较。例如,将字符串和数字操作数进行比较,将其作为浮点数的比较。
条件的由字符转为浮点时候
不以数字开头的字符串都将转换为0。如’abc’、’a123bc’、’abc123’都会转化为0;
以数字开头的字符串转换时会进行截取,从第一个字符截取到第一个非数字内容为止。比如’123abc’会转换为123,’012abc’会转换为012也就是12,’5.3a66b78c’会转换为5.3,其他同理。
避免规则,通过程序处理,尽量使类型与数据库字段保持一致
参考
mysql-8.隐式转换导致索引失效或查出不符合where条件结果
类型转换官方文档
Mysql 性能调试或监控常用指令
show processlist官方手册 https://dev.mysql.com/doc/refman/8.0/en/show-processlist.html
如果有 SUPER 权限,则可以看到全部的线程,否则,只能看到自己发起的线程(这是指,当前对应的 MySQL 帐户运行的线程)
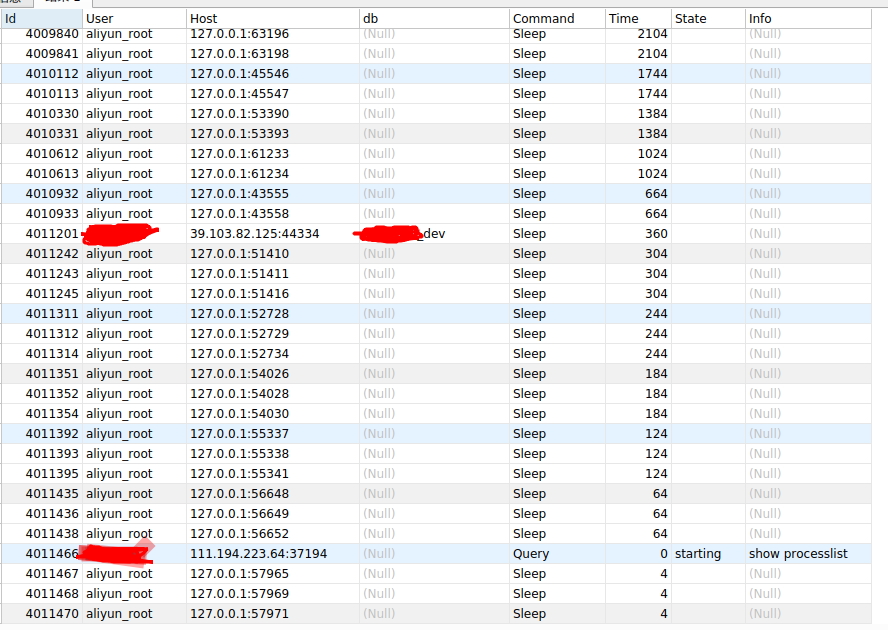
说明各列的含义和用途,
id列:一个标识,你要kill 一个语句的时候很有用。
user列: 显示当前用户,如果不是root,这个命令就只显示你权限范围内的sql语句。
host列:显示这个语句是从哪个ip 的哪个端口上发出的。可用来追踪出问题语句的用户。
db列:显示这个进程目前连接的是哪个数据库。
command列:显示当前连接的执行的命令,一般就是休眠(sleep),查询(query),连接(connect)
通常代表资源未释放,如果是通过连接池,sleep状态应该恒定在一定数量范围内
实战范例:因前端数据输出时(特别是输出到用户终端)未及时关闭数据库连接,导致因网络连接速度产生大量sleep连接,在网速出现异常时,数据库too many connections挂死。
简单解读,数据查询和执行通常只需要不到0.01秒,而网络输出通常需要1秒左右甚至更长,原本数据连接在0.01秒即可释放,但是因为前端程序未执行close操作,直接输出结果,那么在结果未展现在用户桌面前,该数据库连接一直维持在sleep状态
time列:此这个状态持续的时间,单位是秒。
state列:显示使用当前连接的sql语句的状态,很重要的列,后续会有所有的状态的描述,请注意,state只是语句执行中的某一个状态,一个sql语句,已查询为例,可能需要经过copying to tmp table,Sorting result,Sending data等状态才可以完成。
info列:显示这个sql语句,因为长度有限,所以长的sql语句就显示不全,但是一个判断问题语句的重要依据。
这个命令中最关键的就是state列,mysql列出的状态主要有以下几种:
Checking table
正在检查数据表(这是自动的)。
Closing tables
正在将表中修改的数据刷新到磁盘中,同时正在关闭已经用完的表。这是一个很快的操作,如果不是这样的话,就应该确认磁盘空间是否已经满了或者磁盘是否正处于重负中。
Connect Out
复制从服务器正在连接主服务器。
Copying to tmp table on disk
由于临时结果集大于 tmp_table_size,正在将临时表从内存存储转为磁盘存储以此节省内存。
索引及现有结构无法涵盖查询条件,才会建立一个临时表来满足查询要求,产生巨大的恐怖的i/o压力。
很可怕的搜索语句会导致这样的情况,如果是数据分析,或者半夜的周期数据清理任务,偶尔出现,可以允许。频繁出现务必优化之。
Copy to tmp table通常与连表查询有关,建议逐渐习惯不使用连表查询。
实战范例:
某社区数据库阻塞,求救,经查,其服务器存在多个数据库应用和网站,其中一个不常用的小网站数据库产生了一个恐怖的copy to tmp table操作,导致整个硬盘i/o和cpu压力超载。Kill掉该操作一切恢复。
Creating tmp table
正在创建临时表以存放部分查询结果。
deleting from main table
服务器正在执行多表删除中的第一部分,刚删除第一个表。
deleting from reference tables
服务器正在执行多表删除中的第二部分,正在删除其他表的记录。
Flushing tables
正在执行 FLUSH TABLES,等待其他线程关闭数据表。
Killed
发送了一个kill请求给某线程,那么这个线程将会检查kill标志位,同时会放弃下一个kill请求。MySQL会在每次的主循环中检查kill标志位,不过有些情况下该线程可能会过一小段才能死掉。如果该线程程被其他线程锁住了,那么kill请求会在锁释放时马上生效。
Locked 被其他查询锁住了
有更新操作锁定
通常使用innodb(支持行锁定)可以很好的减少locked状态的产生,但是切记,更新操作要正确使用索引,即便是低频次更新操作也不能疏忽。如上影响结果集范例所示。
在myisam的时代,locked是很多高并发应用的噩梦。所以mysql官方也开始倾向于推荐innodb。
Sending data
正在处理 SELECT 查询的记录,同时正在把结果发送给客户端。
Sending data并不是发送数据,别被这个名字所欺骗,这是从物理磁盘获取数据的进程,如果你的影响结果集较多,那么就需要从不同的磁盘碎片去抽取数据,偶尔出现该状态连接无碍。
回到上面影响结果集的问题,一般而言,如果sending data连接过多,通常是某查询的影响结果集过大,也就是查询的索引项不够优化。
如果出现大量相似的SQL语句出现在show proesslist列表中,并且都处于sending data状态,优化查询索引,记住用影响结果集的思路去思考。
Sorting for group
正在为 GROUP BY 做排序。
Sorting for order
正在为 ORDER BY 做排序。
和Sending data类似,结果集过大,排序条件没有索引化,需要在内存里排序,甚至需要创建临时结构排序
Opening tables
这个过程应该会很快,除非受到其他因素的干扰。例如,在执 ALTER TABLE 或 LOCK TABLE 语句行完以前,数据表无法被其他线程打开。 正尝试打开一个表。
Removing duplicates
正在执行一个 SELECT DISTINCT 方式的查询,但是MySQL无法在前一个阶段优化掉那些重复的记录。因此,MySQL需要再次去掉重复的记录,然后再把结果发送给客户端。
Reopen table
获得了对一个表的锁,但是必须在表结构修改之后才能获得这个锁。已经释放锁,关闭数据表,正尝试重新打开数据表。
Repair by sorting
修复指令正在排序以创建索引。
Repair with keycache
修复指令正在利用索引缓存一个一个地创建新索引。它会比 Repair by sorting 慢些。
Searching rows for update
正在讲符合条件的记录找出来以备更新。它必须在 UPDATE 要修改相关的记录之前就完成了。
Sleeping
正在等待客户端发送新请求.
System lock
正在等待取得一个外部的系统锁。如果当前没有运行多个 mysqld 服务器同时请求同一个表,那么可以通过增加 –skip-external-locking参数来禁止外部系统锁。
Upgrading lock
INSERT DELAYED 正在尝试取得一个锁表以插入新记录。
Updating
正在搜索匹配的记录,并且修改它们。
User Lock
正在等待 GET_LOCK()。
Waiting for tables
该线程得到通知,数据表结构已经被修改了,需要重新打开数据表以取得新的结构。然后,为了能的重新打开数据表,必须等到所有其他线程关闭这个表。以下几种情况下会产生这个通知:FLUSH TABLES tbl_name, ALTER TABLE, RENAME TABLE, REPAIR TABLE, ANALYZE TABLE, 或 OPTIMIZE TABLE。
waiting for handler insert
INSERT DELAYED 已经处理完了所有待处理的插入操作,正在等待新的请求。
Waiting for net, reading from net, writing to net
偶尔出现无妨
如大量出现,迅速检查数据库到前端的网络连接状态和流量
案例:因外挂程序,内网数据库大量读取,内网使用的百兆交换迅速爆满,导致大量连接阻塞在waiting for net,数据库连接过多崩溃
大部分状态对应很快的操作,只要有一个线程保持同一个状态好几秒钟,那么可能是有问题发生了,需要检查一下。还有其它的状态没在上面中列出来,不过它们大部分只是在查看服务器是否有存在错误是才用得着。
show profiles
show profile for query 1官方手册:https://dev.mysql.com/doc/refman/8.0/en/show-profile.html
show status
flush status
show global status
show engine innodb status(老版 show innodb status) show tables from information_schemaexplain官方手册 https://dev.mysql.com/doc/refman/8.0/en/using-explain.html
详细介绍:https://www.yangliuan.cn/?p=145
参考链接
MySql索引的使用总结
所有存储引擎都支持每个表至少 16 个索引,总索引长度至少为 256 字节。
组合索引KEY(col1,col2) 联合主键索引 PARIMARY KEY( col1,col2)
最左匹配原则
创建了key(k1,k2,k3),相当于创建了(k1)、(k1,k2) 和 (k1,k2,k3) 三个索引
索引全部命中的情况where条件不区分顺序 where k1 = xxx and k2 = xxx and k3 = xxx 等同于 where k3 = xxx and k2 = xxx and k1 = xxx 查询优化器会处理并使用索引
where k1 = xxx 或 where k1 = xxx and k2 = xxx 使用索引 where k2 = xxx 或 where k3 = xxx 无法使用索引
当查询优化器发现最优索引时,并不会遵循最左匹配原则,而是使用最优查询,如下图k1,k2,k3为连续字段时,不按最左匹配查询还是会命中索引,此时k1,k2,k3被查询优化器当成了一个字段,单次查询k1,k2,k3都会命中
EXPLAIN select * from 3k where k2 = 'sdfdsa'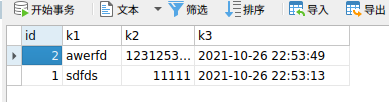

当k1,k2,k3不在连续中间被其它字段隔开时
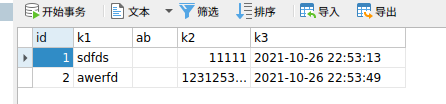
相同的查询语句将不会命中索引

联合索引,那么 key 也由多个列组成,同时,索引只能用于查找 key 是否存在(相等),遇到 范围查询(>、<、between、like 左匹配)等就不能进一步匹配了,后续退化为线性查找。因此,列的排列顺序决定了可命中索引的列数。
如有索引 (a, b, c, d),查询条件 a = 1 and b = 2 and c = 3 and d > 4,则会在每个节点依次命中 a、b、c,无法命中 d。也就是最左前缀匹配原则。
不需要考虑 =、in 等的顺序,MySQL 会自动优化这些条件的顺序,以匹配尽可能多的索引列。
如有索引 (a, b, c, d),查询条件 c > 3 and b = 2 and a = 1 and d < 4 与 a = 1 and c > 3 and b = 2 and d < 4 等顺序都是可以的,MySQL 会自动优化为 a = 1 and b = 2 and c > 3 and d < 4,依次命中 a、b。
离散度高原则,选择性(离散性)高的优先,即数据重复率低的列,像性别字段只有男/女两个值,因此选择性很差
离散度的公式是 count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是 1,而一些状态、性别字段可能在大数据面前区分度就是 0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要 join 的字段我们都要求是 0.1 以上,即平均 1 条扫描 10 条记录。
字符串字段过长时可以使用,索引前缀,截取字段前一部分的值作为索引
CREATE TABLE test (blob_col BLOB, INDEX(blob_col(10)));Range类型 要使用单字段索引
当使用 =、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN、LIKE 或 IN() 运算符中的任何一个将键列与常量进行比较时,可以使用范围
where min <= 1 and max >= 1 语句使用min和max联合索引并不会生效,应该使用min和max的两个单字段索引索引失效情况总结
查询条件包含 or,会导致索引失效
隐式类型转换,会导致索引失效,where条件左边字段类型为字符串类型时,传入其他类型会触发
like 通配符会导致索引失效,注意:”ABC%” 不会失效,会走 range 索引,”% ABC” 或 “%ABC%” 索引会失效
联合索引,最左匹配原则被中断时
对索引字段进行函数运算,列运算(算术,逻辑,移位等) 注意是对字段做运算,对字段的值做运算时并不影响,如下图
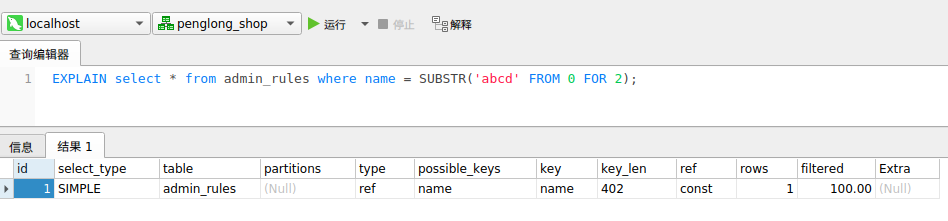
索引字段上使用(!= 或者 < >,not in)时,会导致索引失效
索引字段上使用 is null, is not null,可能导致索引失效
相 join 的两个表的字符编码不同,不能命中索引,会导致笛卡尔积的循环计算
mysql 优化器判断使用全表扫描要比使用索引快,则不使用索引
简单索引和联合索引如何抉择?
能扩展就不要新建索引。如果已有索引 (a),想建立索引 (a, b),尽量选择修改索引 (a) 为索引 (a, b),这样占用空间最小效果一致。
如果已有索引 (a, b),则不需要再建立索引 (a),但是如果有必要,则仍然需考虑建立索引 (b)。
索引尽量少原则
虽说索引可以加速查询,但索引未必是越多越好,因为:
- 第一点、数据的增删都会涉及到随索引的修改,索引越多维护成本越高,所以频繁进行数据操作的表,不要建立太多的索引;
- 第二点、索引越多也意味着存储空间需要越大;
因为索引是有代价的,所以用不到的索引,也需要清理掉。
如何定位哪些页面和接口需要加索引?
最简单直接方法是:往数据库里生成 100 万条数据,然后做黑盒测试。
数据有了以后,假装你是一个正常的用户,然后不断地点来点去,做各种操作,点赞、收藏、发文章、评论等,看看哪个动作或者页面加载很慢,就记录下来
如果使用laravel框架可以用telescope或者debug工具查看执行的sql语句,对访问频率高的接口和页面,增加索引,优化查询
参考
Mysql Explain命令
官方手册 :https://dev.mysql.com/doc/refman/8.0/en/using-explain.html
Explain命令 查看语句的执行计划,用于sql语句优化

属性说明:
select_type:select 的语句的查询类型
| 类型值 | 类型值说明 |
SIMPLE | 简单SELECT(不使用UNION或子查询等) |
PRIMARY | 最外面的SELECT |
UNION | UNION中的第二个或后面的SELECT语句 |
DEPENDENT UNION | UNION中的第二个或后面的SELECT语句,取决于外面的查询 |
UNION RESULT | UNION的结果 |
SUBQUERY | 子查询中的第一个SELECT |
DEPENDENT SUBQUERY | 子查询中的第一个SELECT,取决于外面的查询 |
| DERIVED | 派生表 |
| DEPENDENT DERIVED | 派生表依赖于另一个表 |
| MATERIALIZED | 物化子查询,子查询来自视图 |
| UNCACHEABLE SUBQUERY | 一个子查询,其结果不能被缓存,必须对外层查询的每一行进行重新评估 |
| UNCACHEABLE UNION | UNION中的第二个或以后的选择,属于不可缓存的子查询(参见不可缓存的子查询) |
table:显示这一行的数据是关于哪张表的
partitions: 被查询记录所在的分区,没有返回null,分区功能参考mysql分区功能
type:这列最重要,显示了连接使用了哪种类别,有无使用索引,是使用Explain命令分析性能瓶颈的关键项之一
| 类型值 | 类型值说明 |
| system | 该表只有一行(= 系统表)。这是 const 连接类型的特例 |
| const | 该表最多有一个匹配行,在查询开始时读取。因为只有一行,该行中该列的值可以被优化器的其余部分视为常量。 const 表非常快,因为它们只被读取一次。主键或唯一索引时类型为常量 |
| eq_ref | 对于前面表中的每个行组合,从该表中读取一行。除了 system 和 const 类型之外,这是最好的连接类型。当连接使用索引的所有部分并且索引是 PRIMARY KEY 或 UNIQUE NOT NULL 索引时使用它 |
| ref | 所有具有匹配索引值的记录都从这个表中读出,用于前面表中的每一个记录组合。如果连接只使用键的最左边的前缀,或者键不是PRIMARY KEY或UNIQUE索引(换句话说,如果连接不能根据键值选择一条记录),就使用ref。如果使用的键只与几条记录相匹配,这就是一个好的连接类型 |
| fulltext | 全文索引,类搜索引擎功能 |
| ref_or_null | 这种连接类型就像ref,但增加了MySQL对包含NULL值的行进行额外的搜索。这种连接类型的优化在解决子查询时最常使用。在下面的例子中,MySQL可以使用一个ref_or_null连接来处理ref_table |
| index_merge | 这种连接类型表明使用了索引合并优化。在这种情况下,输出行中的key列包含了所使用的索引的列表,key_len包含了所使用的索引的最长的key部分的列表。更多信息,请参见章节8.2.1.3,”索引合并优化“ |
| unique_subquery | 对于以下形式的某些 IN 子查询,此类型替换 eq_ref:value IN (SELECT primary_key FROM single_table WHERE some_expr) |
| index_subquery | 这种连接类型类似于 unique_subquery。它取代了 IN 子查询,但它适用于以下形式的子查询中的非唯一索引:value IN (SELECT key_column FROM single_table WHERE some_expr) |
| range | 只检索给定范围内的行,使用索引来选择行。输出行中的key列表明使用的是哪个索引。key_len包含了所使用的最长的关键部分。对于这种类型,ref列是NULL |
| index | 索引连接类型与ALL相同,只是对索引树进行扫描。这有两种情况。 如果索引是查询的覆盖索引,并且可以用来满足表的所有数据要求,那么只有索引树被扫描。在这种情况下,Extra列显示使用索引。只扫描索引的速度通常比ALL快,因为索引的大小通常比表的数据小。 全表扫描是使用从索引中读出的数据来按索引顺序查找数据行。使用索引不会出现在Extra列中。 当查询只使用属于一个索引的列时,MySQL可以使用这种连接类型。 |
| ALL | 没有使用任何索引,使用了全表扫描,性能非常差 |
range示例说明
当使用 =、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN、LIKE 或 IN() 运算符中的任何一个将键列与常量进行比较时,可以使用范围:
SELECT * FROM tbl_name
WHERE key_column = 10;
SELECT * FROM tbl_name
WHERE key_column BETWEEN 10 and 20;
SELECT * FROM tbl_name
WHERE key_column IN (10,20,30);
SELECT * FROM tbl_name
WHERE key_part1 = 10 AND key_part2 IN (10,20,30);结果值从好到坏依次是:一般来说,得保证查询至少达到range级别,最好能达到ref,否则就可能会出现性能问题。
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALLpossible_keys:列指出MySQL能使用哪个索引在该表中找到行
当前查询可用的索引 多个逗号分隔
key:显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL
查询优化器实际选择的索引
key_len:显示MySQL决定使用的键长度。如果键是NULL,则长度为NULL。使用的索引的长度。在不损失精确性的情况下,长度越短越好
ref:显示使用哪个列或常数与key一起从表中选择
该ref列显示哪些列或常量与列中指定的索引进行比较以 key从表中选择行。
如果值为func,则使用的值是某个函数的结果。要查看哪个功能,请使用 SHOW WARNINGS以下内容 EXPLAIN查看扩展 EXPLAIN输出。该函数实际上可能是一个运算符,例如算术运算符。
rows: rows列表示MySQL认为它必须检查以执行查询的行数,对于InnoDB表,这个数字是一个估计值,不一定准确
filtered: 表按照条件过滤行数的百分比
过滤列表示被表条件过滤的表行的估计百分比。最大值是100,这意味着没有发生过滤的行。从100开始递减的值表示过滤量的增加。rows显示了被检查的行的估计数量,rows × filtered显示了与下面表格连接的行的数量。例如,如果rows是1000,而filtered是50.00(50%),那么与下表中连接的行数是1000×50%=500
Extra:附加信息 包含MySQL解决查询的详细信息,也是关键参考项之一。
这一列包含关于MySQL如何解决查询的额外信息。关于不同值的描述,见EXPLAIN额外信息。
没有与Extra列相对应的单一JSON属性;然而,可能出现在这一列中的值被暴露为JSON属性,或作为消息属性的文本
具体信息看官方文档查询
https://dev.mysql.com/doc/refman/8.0/en/explain-output.html#explain-extra-information
其他一些Tip:
- 当type 显示为 “index” 时,并且Extra显示为“Using Index”, 表明使用了覆盖索引。
EXPLAIN ANALYZE
select * 和 select 具体字段差别